[Study] 머신러닝 시스템 디자인 패턴 - Chapter 3
Chapter 3
3.1 학습환경과 추론환경
3.1.1 시작하기
- 학습을 빠르게 반복하는 것에 치중하다보면…
- 가독성이 낮고
- 테스트가 작성되어 있지 않으며
- 재현성도 보장하지 않는
코드가 생길 수 있다.
- 학술적인 목적이라면 문제 X → 비즈니스 목적으로 개발한다면 가치 창출이 중요.
- 성공적으로 릴리즈해서 실제 환경에서 추론할 수 없는 모델이라면 비용 낭비이다.
- 이번 챕터의 중점
- 실제 시스템으로 릴리즈하는 방법
- 안티 패턴 알아보기
3.1.2 학습환경과 추론환경
-
학습환경과 추론환경은 목적도 다르고 비용구조가 다르다. 전혀 다른 리소스, 코드, 라이브러리가 사용될 수 있다.
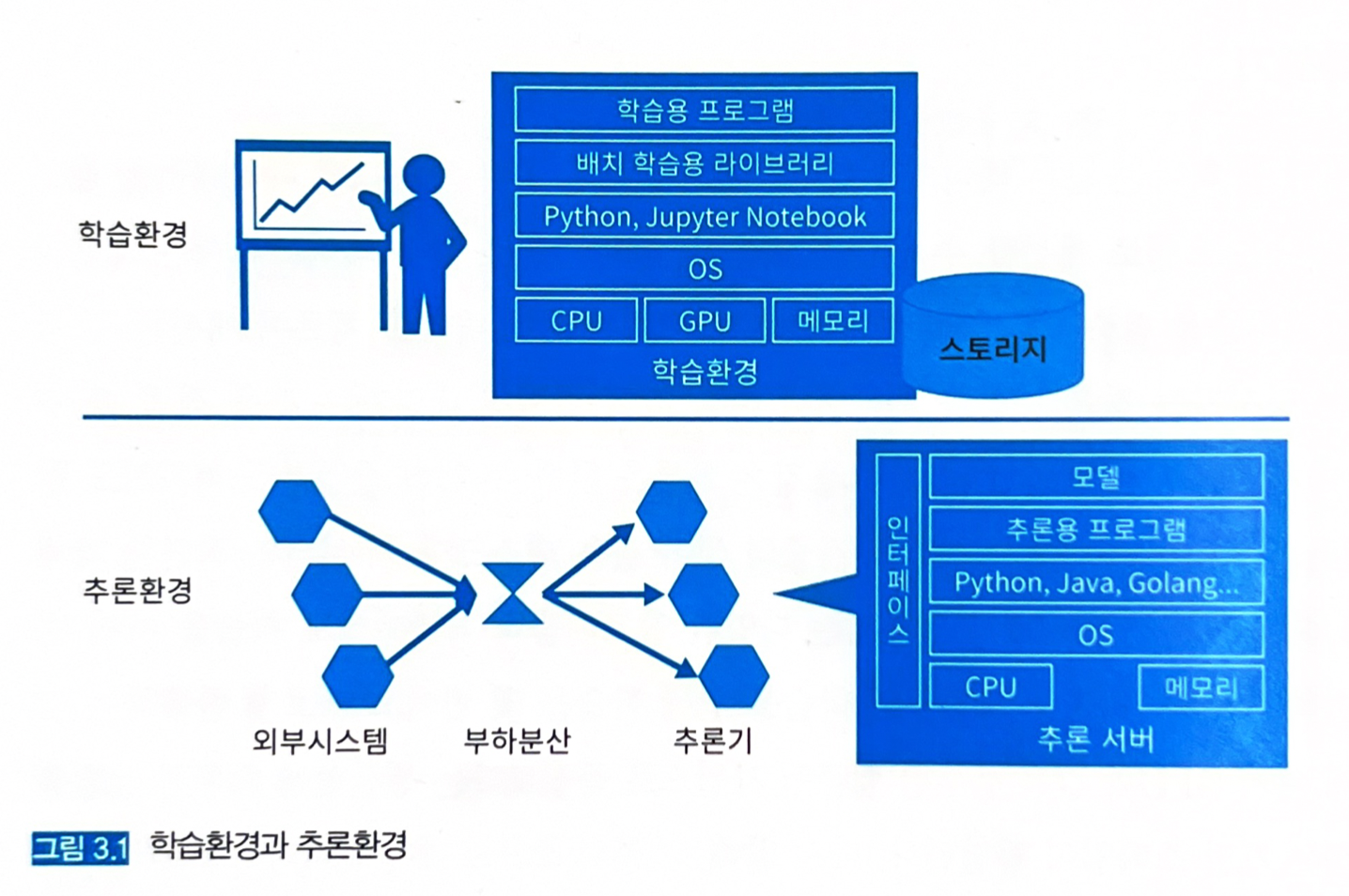
- 릴리즈 시 문제점들은 이러한 괴리에 기인하는 부분이 많다.
- 학습 페이즈에서는 초기 비용이 컴퓨팅 자원에 투자되며, 코드 리뷰나 단위 테스트, 리팩터링은 거의 없다.
- “실험 당사자만이 이해하고 실행 가능한” 코드로 학습이 이뤄지는 문제가 생긴다.
- 추론 페이즈에서는 실제 시스템에 추론 코드가 포함되어 다른 시스템과 연계 가동되고 운용된다.
- 추론기가 장애가 발생하거나 잘못된 추론을 하는 경우, 비즈니스에 손실이 생기기 때문에 즉시 복구해야 한다.
- 엔지니어는 문제 코드를 파악하고, 시스템을 이해하고, 장애를 특정, 개선할 수 있어야 한다.
- 이러한 트러블슈팅의 효율을 높이려면 시스템 추적이 가능하도록 코드를 설계하고 작성해야 하며, 특정 인원만이 실행할 수 있게 해서는 안 된다.
- 추론환경은 계속 가동되어야 한다.
- 비용 문제 발생 → 필요 자원을 최소한으로 조정하고, 부하에 따라 오토 스케일하는 설계가 바람직하다.
- 코드 안정성 → 학습환경에서는 즉시 코드 수정이 가능하나, 추론환경에서는 다른 시스템에 대한 영향까지도 고려하며 대응해야 한다.
- 학습 페이즈에서는 초기 비용이 컴퓨팅 자원에 투자되며, 코드 리뷰나 단위 테스트, 리팩터링은 거의 없다.
- 학습, 추론환경에서 공통으로 사용하는 컴포넌트도 있다.
- 모델 파일 (당연히 같은 것을 사용한다).
- 입출력 데이터의 타입 (Float16 등)과 형태 (3차원 배열 등) → 바뀌는 경우는 없으며, 바뀌어서도 안 된다.
- 학습과 추론 양쪽 환경을 모두 파이썬으로 개발하다 보면 어느 쪽이든 데이터 타입을 직접 정의하지 않는 경우가 생긴다. → 데이터 타입이 다르면 잘못된 추론 결과가 출력될 수 있다.
3.2 안티 패턴 (버전 불일치 패턴)
- 모델을 추론기로 릴리즈할 때 가장 문제가 되는 점 → 학습환경과 추론환경의 차이
- OS, 라이브러리
3.2.1 상황
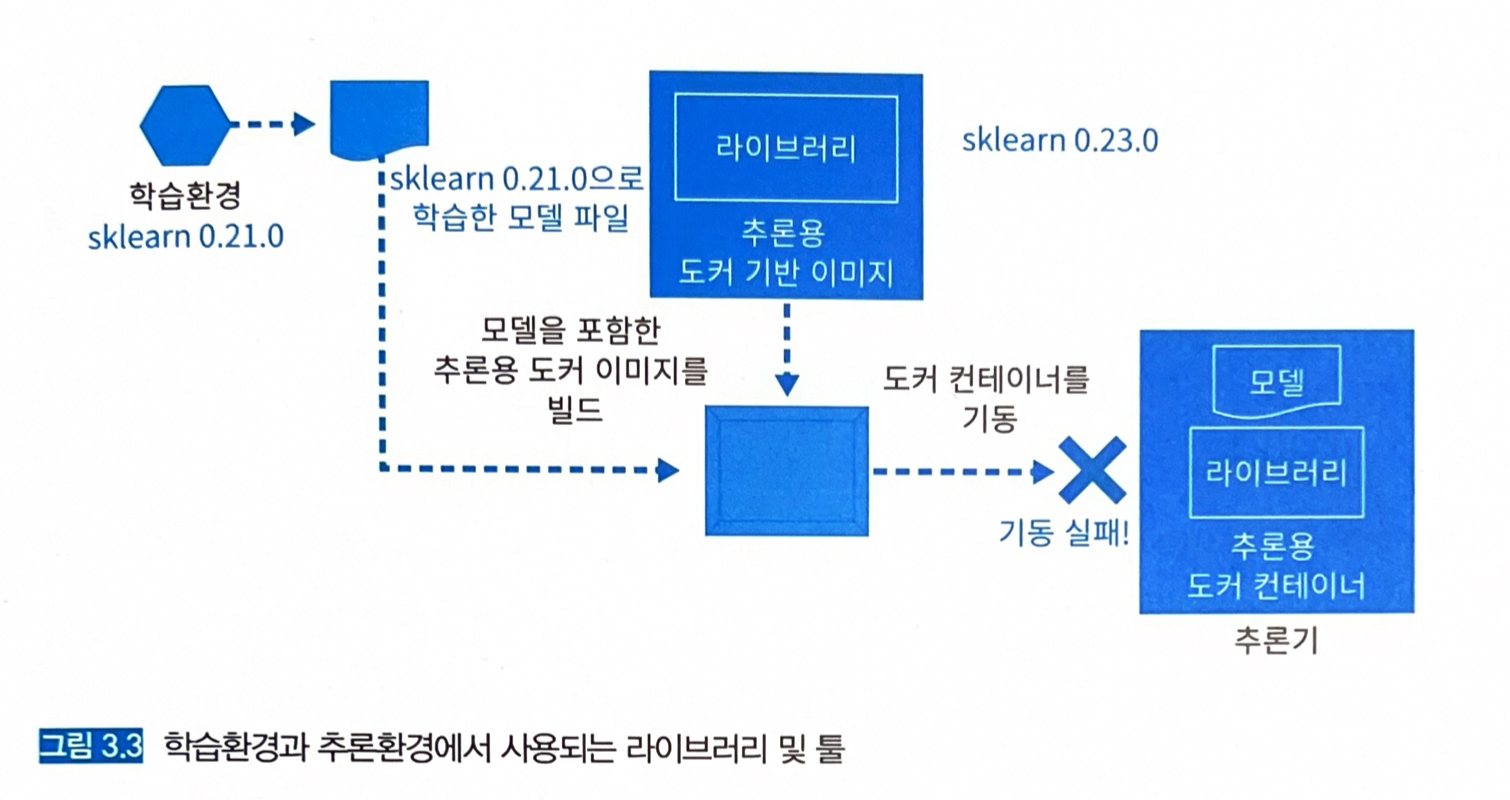
- 버전 불일치 오류 → 학습환경과 추론환경에서 같은 라이브러리를 사용하고 있으나, 버전이 일치하지 않는 경우.
- 모델 로딩 오류 → 추론기로 모델을 불러올 수 없는 경우.
- 잘못된 추론 오류 → 추론 결과가 학습환경에서 예상했던 추론 결과와 일치하지 않는 경우.
3.2.2 구체적인 문제
- 언어와 라이브러리 버전을 일치시켜야 한다. → 파이썬 2.7로 모델을 학습하고, 추론기에서 파이썬 3.9를 사용하면 당연히 문제가 된다.
- GPU 장비, GPU 드라이버, CUDA, CuDNN 등을 고려해야 한다.
- 버전 호환성 문제 회피 방법: ONNX (https://onnx.ai/)
- ONNX (Open Neural Network Exchange)
- 머신러닝 모델의 중간 표현.
- 서로 다른 라이브러리에서 학습한 모델을 공통된 ONNX 형식으로 변환해주는 역할.
- ONNX 형식으로 변환한 모델은 ONNX Runtime이라고 하는 공통의 추론엔진으로 가동시킬 수 있다.
- 모든 머신러닝 라이브러리를 지원하는 것은 아니다 → 지원하는 버전의 호환 여부를 공개하고 있으니 확인하고 진행해야 한다.
- ONNX (Open Neural Network Exchange)
- 공통으로 사용되는 라이브러리는 버전까지 포함해서 공유하는 구조를 만들어 두는 것이 좋다.
pip install -r requirements.txt를 추론환경에서 실행해 전체 설치를 할 수 있다.- 목록이 없을 경우
pip list freeze > requirements.txt를 실행하면 만들 수 있다. - 적어도 버전의 불일치가 발생하는 사태를 막을 수 있다.
3.2.3 이점
- 라이브러리 버전에 따른 호환성을 검증할 수 있음.
3.2.4 과제
- 모델을 불러올 수 없음.
- 모델을 불러올 수는 있지만, 추론 결과가 학습할 때와 다름.
3.2.5 해결방법
- 학습환경에서 사용한 라이브러리와 버전을 출력해서 추론기의 개발에 공유하는 구조나 워크플로를 구성함.
3.3 모델의 배포와 추론기의 가동
- 모델 파일이 수MB 이상의 사이즈인 경우
- 배포/교체 과정에서 네트워크와 추론기 로딩만으로도 수십 초가 소요되기도 한다.
- 시스템이 멈추지 않도록 배포하고 갱신해야 한다.
- 카나리 릴리즈 방식으로 기존 추론기와 새로운 추론기의 가동을 병행해 점차 새로운 추론기를 추가하며, 충분한 시간을 두고 교체하는 것이 좋다.
- 배포 대상 추론기와의 호환성
- 추론기에 설치된 라이브러리가 모델과 일치해야 하며, 라이브러리 버전을 관리해 두는 것이 좋다.
- 인벤토리 관리
- 추론기의 OS나 라이브러리, 버전, 가동 중인 모델, 데이터 형식, 모델의 목적 (분류, 회귀, 클러스터링 등)을 관리해야 한다.
- 세월이 흘러 담당 엔지니어의 이동이 발생하면 히스토리를 알 수 없게 된다.
3.3.2 학습환경과 추론환경의 라이브러리와 버전 선정
- 라이브러리의 취약성과 업데이트를 고려해야 하여 학습환경의 라이브러리를 업데이트하거나 대체 라이브러리를 사용해야 한다.
3.3.3 추론기에 모델 포함하기
- 추론기로 가동할 때 필요한 컴포넌트
- 인프라: 서버, CPU, 메모리, 스토리지, 네트워크
- OS: Linux, Windows 등
- 런타임 (모델을 불러오고 가동하기 위한 라이브러리): ONNX Runtime이나 TensorFlow Serving 등.
- 모델 파일: 학습된 모델 파일
- 프로그램: 추론 요청에 대해 전처리, 추론, 후처리를 수행하고 응답하는 프로그램.
- 인프라, OS, 런타임은 기존의 것을 이용하는 경우가 많고, 직접 구성하는 경우는 드물다.
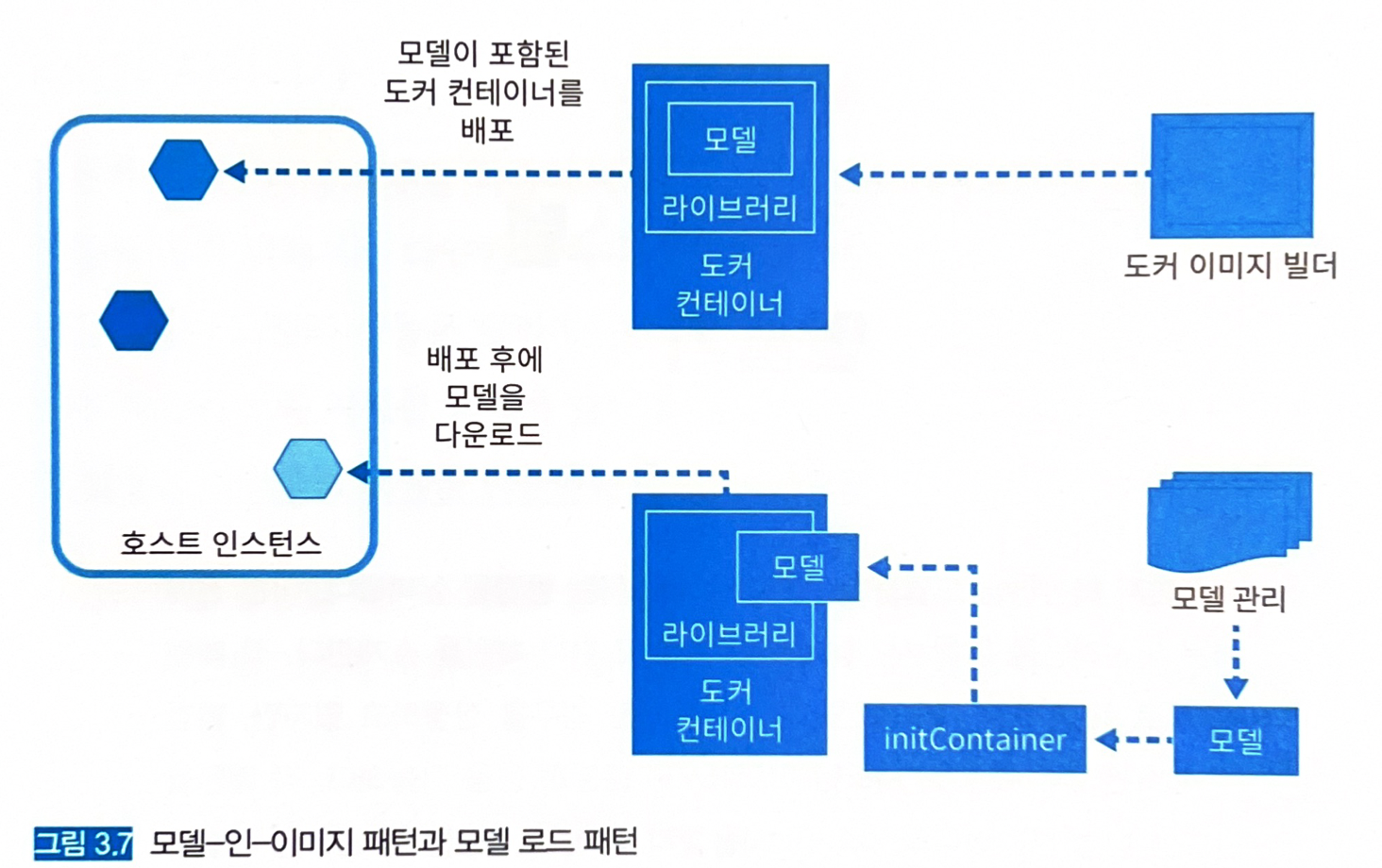
- 모델 릴리즈 패턴 2가지
- 모델-인-이미지 패턴
- 모델 로드 패턴
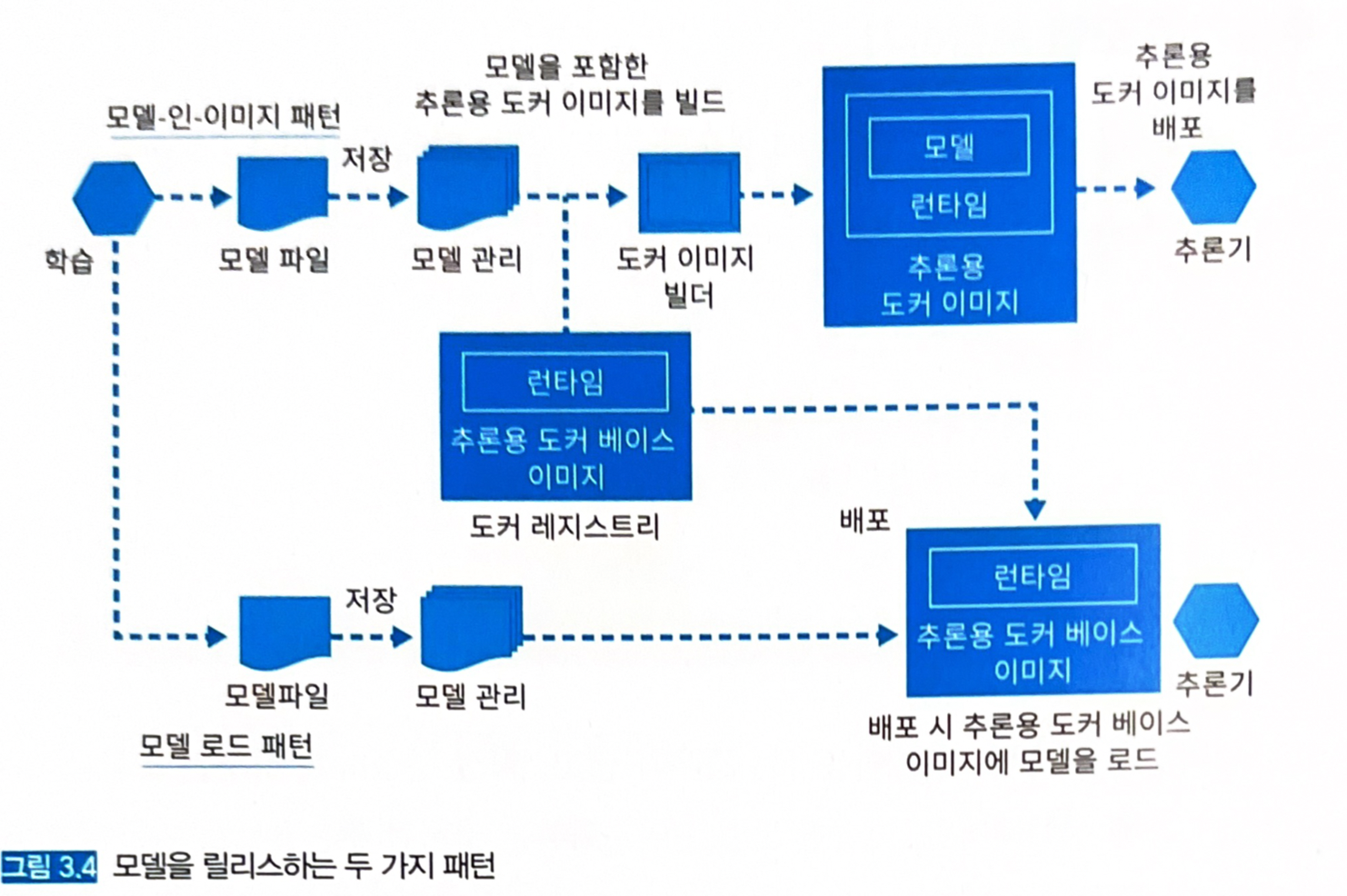
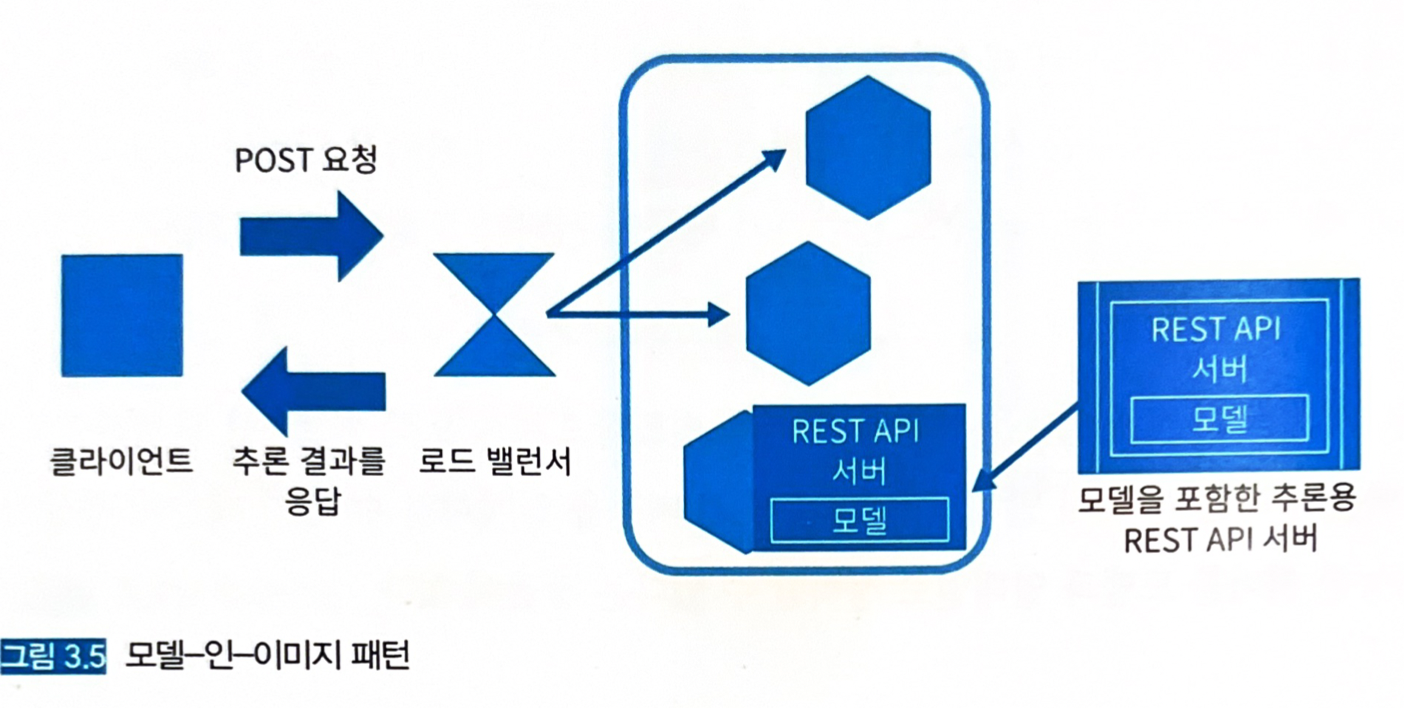
3.4 모델-인-이미지 패턴
- 추론기의 이미지에 모델 파일을 포함해서 빌드하는 방식.
- 모델을 포함해서 빌드하기 때문에 해당 모델의 전용 추론기 이미지를 생성할 수 있다.
3.4.1 유스케이스
- 서버 이미지와 추론 모델의 버전을 일치시키고 싶은 경우.
- 추론 모델에 개별 서버 이미지를 준비하는 경우.
3.4.2 해결하려는 과제
- 서버로 모델을 불러와서 추론이 가능한 상태로 만들어야 한다.
- 오직 빌트인 모델만을 가동시키는 서버를 구축하여 서버-모델을 일대일로 정리한다.
3.4.3 아키텍처
- 사전에 클라우드에서 빌드한 서버 이미지를 이용해 서버를 가동시킨다.
- 추론 서버의 이미지에 학습이 끝난 모델을 포함시키기 때문에 학습과 서버 이미지의 구축을 워크플로로 만들 수 있다.
- 아래와 같이 모델을 포함한 추론용 서버 이미지를 빌드하고, 추론기를 준비할 때는 서버 이미지를 pull한 뒤 기동시킨다.
3.4.4 구현
- 서버 부팅과 동시에 바로 가동되게 구성한다.
- 추론기를 웹 API로 가동시켜 GET/POST 요청으로 접근하게 한다.
- Docker, Kubernetes, Python 3.8
- Gunicorn + FastAPI
- scikit-learn
- ONNX Runtime
- 학습이 끝난 모델은 Dockerfile을 준비하여 도커 이미지에 포함하고, 이미지를 푸쉬해둔다.
- Dockerfile 코드 생략 (코드 3.2 참고)
- 쿠버네티스에서는 YAML을 통해 사용할 리소스를 정의한다.
- 도커 이미지나 네트워크에 관한 정의를 포함하는데, 이렇게 정의한 파일을 매니페스트 (Manifest)라 한다. (e.g.,
deployment.yaml)
- 도커 이미지나 네트워크에 관한 정의를 포함하는데, 이렇게 정의한 파일을 매니페스트 (Manifest)라 한다. (e.g.,
-
쿠버네티스 매니페스트


- 배포를 통해 정상적인 추론이 가능함을 확인한다
3.4.5 이점
- 가동 확인이 끝난 서버와 모델의 편성을 하나의 추론용 서버 이미지로 관리가 가능함.
- 서버와 모델을 일대일 대응으로 관리할 수 있어 운용상 간편함.
3.4.6 검토사항
- 학습한 모델의 수만큼 서버 이미지의 수도 늘어나는 구조다. → 불필요한 서버 이미지를 삭제하여 스토리지를 절약해야 한다.
- 추론기의 가동 시간만큼 스케일 아웃의 소요 시간이 늘어난다. → 서버의 베이스 이미지를 미리 다운로드 받아 둔다.
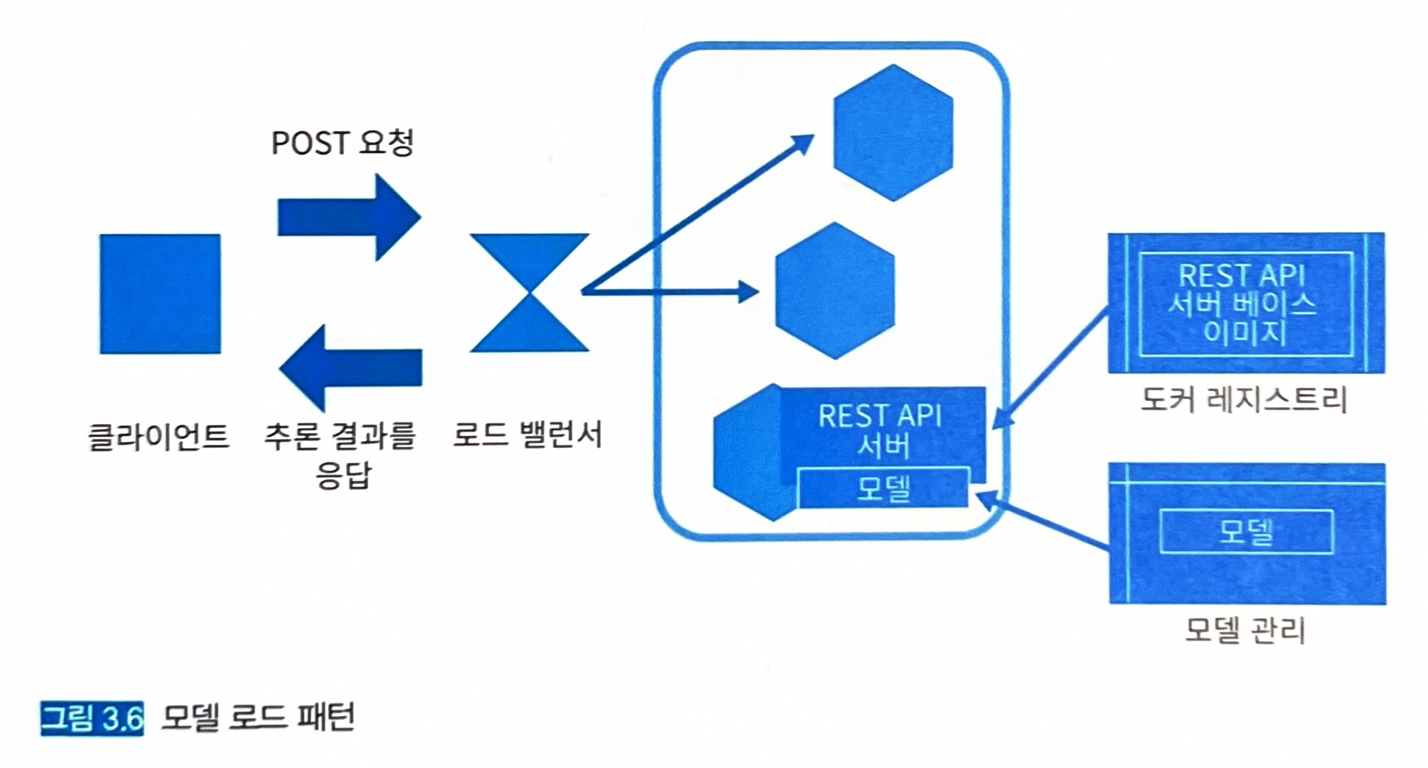
3.5 모델 로드 패턴
3.5.1 유스케이스
- 서버 이미지 버전보다 추론 모델의 버전을 더 빈번하게 갱신하는 경우.
- 동일한 서버 이미지로 여러 종류의 추론 모델 가동이 가능한 경우.
3.5.2 해결하려는 과제
- 만약 동일한 전처리 기법과 동일한 의사결정나무 모델을 다른 데이터셋으로 여러 번 학습하는 경우
- 학습할 때마다 서버 이미지를 빌드하게 된다.
- 데이터셋만 지속적으로 바꾸어 가며 새로운 모델을 생성하는 것이 바람직하다.
- 이런 경우엔 모델 로드 패턴이 최적의 모델 배포 방법이다.
3.5.3 아키텍처
- 서버 이미지와 모델을 별도로 관리하여, 서버 이미지를 경량화할 수 있다.
- 범용성을 높여 동일한 서버 이미지를 여러 추론 모델에 응용할 수 있다.
- 추론기를 배치할 때 서버 이미지를 pull한 뒤 추론기를 기동하고, 이후에 모델 파일을 취득해서 추론기를 본격적으로 가동한다.
- 환경변수 등으로 추론 서버에서 가동하는 모델을 유연하게 변경할 수도 있다.
- 단점
- 모델이 라이브러리 버전에 의존적일 경우, 서버 이미지의 버전 관리와 모델 파일의 버전 관리를 별도로 수행해야 한다 → 운용 부하.
3.5.4 구현
- 모델 파일을 도커 이미지에 포함시키지 않고, 도커 컨테이너를 기동할 때 모델을 다운로드한다.
- 모델 파일은 스토리지 (AWS, GCP)에 저장해 두고, 필요할 때 다운로드할 수 있게 한다.
- 모델 파일의 다운로드는 쿠버네티스의
initContainer를 사용한다.- 컨테이너를 기동하기 전에 필요한 초기화를 실행할 수 있다.
- 파일 다운로드 파이썬 코드 생략 (코드 3.4 참고)
- 추론기의 Dockerfile에는 모델 파일을 포함시키지 않은 채 모델을 실행하기 위한 코드를 빌드한다.
- 추론기 Dockerfile 코드 생략 (코드 3.5 참고)
-
쿠버네티스 매니페스트



3.5.5 이점
- 서버 이미지의 버전과 모델 파일의 버전 분리 가능
- 서버 이미지의 응용성이 향상
- 서버 이미지 경량화
3.5.6 검토사항
- 모델 로드 패턴에서는 서버 이미지와 모델의 버전 불일치를 해결하는 구조가 필요하다.
- 모델의 갱신은 서버 이미지의 갱신에 뒤따라야 한다.
- 만약 버그로 인해 모델 다운그레이드를 해야 한다면 서버 이미지도 되돌릴 수 있는 상태를 만드는 것이 중요하다.
3.5 모델의 배포와 스케일 아웃
- 두 패턴은 추론기의 릴리즈뿐만 아니라 스케일러빌리티 (Scalability)의 관점에서 차이가 있다.
- 모델-인-이미지 패턴에서는 도커 이미지의 사이즈가 커지는 경향이 있어 소요 시간이 오래 걸린다.
- 모델 로드 패턴에서는 도커 이미지의 다운로드가 추가로 발생하지 않고, 모델을 다운로드하는 것 만으로도 추론기를 기동시킬 수 있다.
- 항상 모델 로드 패턴이 빠른 것은 아니다. → 모델 파일의 리드 타임이 느린 경우
- 초기 기동: 모델 로드 패턴 (빠름) > 모델-인-이미지 패턴 (느림)
- 스케일 아웃: 모델 로드 패턴 (느림) < 모델-인-이미지 패턴 (빠름)
- 클라우드의 경우 네트워크 대역이 문제가 되는 경우가 적지만, 온프레미스 등 네트워크 대역에 제한이 있는 환경에서는 도커 이미지나 모델의 다운로드 속도가 항상 고려해야 할 지표가 된다.
- 신속한…
- 모델-인-이미지 패턴을 위해서는: 도커 이미지 용량을 줄여야 한다.
-
모델 로드 패턴을 위해서는: 모델 다운로드 속도를 높이기 위한 대책 (추론기 근처에 저장, CDN 이용 등)