[Study] 머신러닝 시스템 디자인 패턴 - Chapter 4 (part 1)
Chapter 4.1 - 4.5
4.1 시스템을 만들어야 하는 이유
- 모델을 로컬에만 추론할 수 있게 구성하는 것은 도움이 되지 않으며, 다른 소프트웨어들과 조합해 모델이 호출되는 구조를 갖춰야 한다.
4.1.1 시작하기
- 모델을 실제 시스템에 포함하는 방법을 패턴화하고 각 패턴의 구현 방법, 장점과 검토 사항들에 대해 살펴본다.
4.1.2 머신러닝의 실용화
-
모델을 담은 추론기를 외부 시스템과 연계해야 한다.
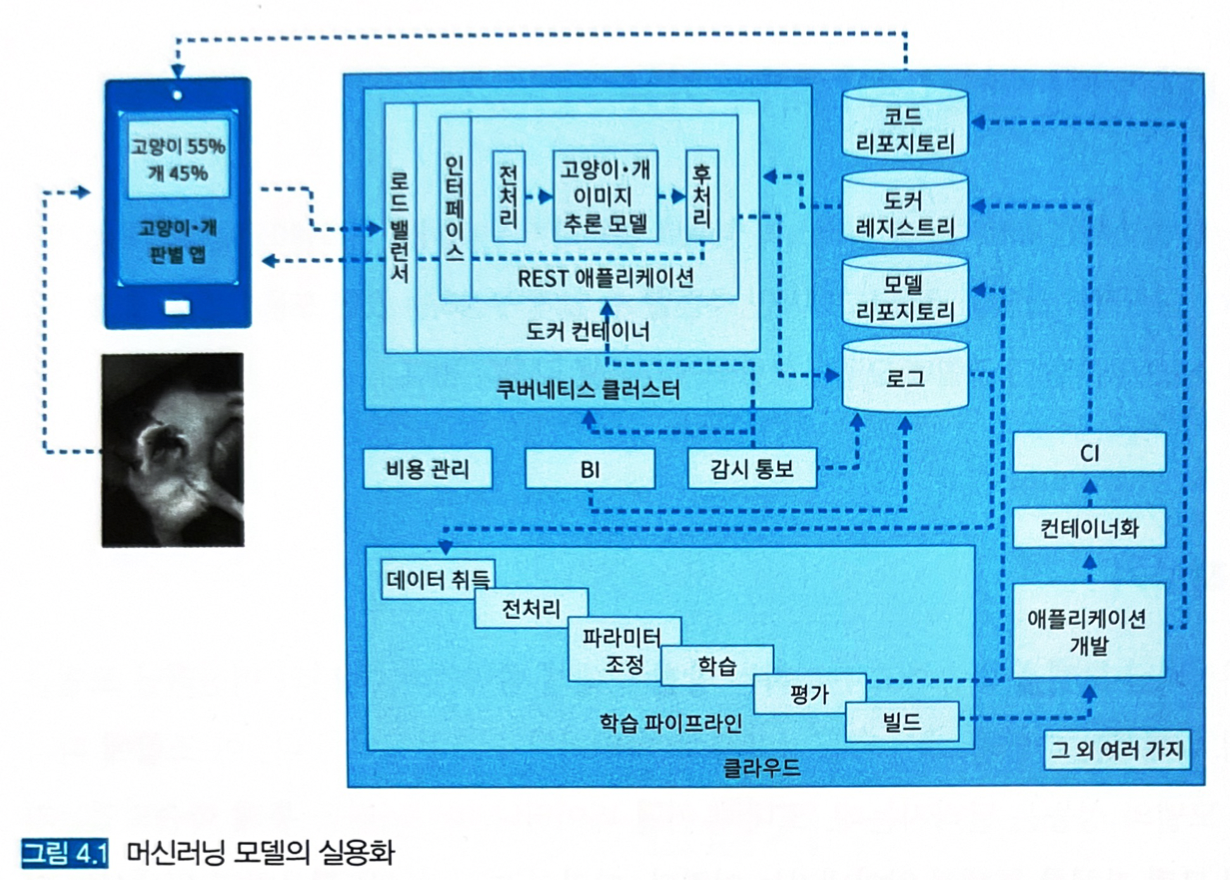
-
이번 장에서 웹 싱글 패턴, 동기 추론 패턴 등 여러 추론기 패턴을 설명한다.
4.2 웹 싱글 패턴
- 한 대의 웹 API 서비스에 머신러닝 추론 모델을 포함한다 → API에 데이터와 함께 요청을 보내면 추론 결과를 얻는다.
- 가장 간단하면서도 기초적인 구성이다.
4.2.1 유스케이스
- 추론기를 신속하게 릴리즈해서 모델의 성능을 검증하고 싶은 경우
4.2.2 해결하려는 과제
- 모델이 최상의 정답률을 발휘하는 시기는 학습이 끝난 직후다.
- 계절성이 짙은 서비스라면 빠르게 모델을 실제 비즈니스에 투입하고 가치를 창출하는 것이 중요할 수 있다.
4.2.3 아키텍처
- 한 대의 서버가 필요로 하는 최소한의 기능만을 개발하고, 대부분에 시스템에서 사용이 가능한 REST API로 인터페이스를 구성하는 것이 좋다 (gRPC도 좋다).
- Flask나 FastAPI로 구현하고, 파이썬을 통해 모델을 로드하고 추론한다.
- 머신러닝의 추론은 대부분 Stateless기 때문에 DB나 스토리지 등의 데이터를 영속적으로 보존하는 Persistent layer를 준비하지 않고 웹 서버 한 대로 구성할 수 있다. (여러 대라면 로드 밸런서를 도입해 부하를 분산한다)
4.2.4 구현
- 추론 모델: Iris 데이터셋을 서포트 벡터 머신을 분류하는 모델.
- 추론기: FastAPI, ONNX Runtime
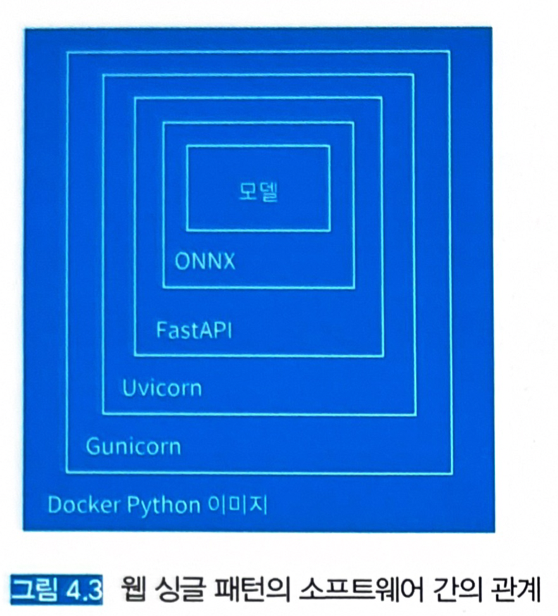
- FastAPI는 파이썬 기반의 웹 프레임워크로 Uvicorn을 통한 비동기 처리와 Pydantic을 통한 구조적 데이터 정의를 지원한다.
- Uvicorn은 ASGI (Asynchronous Server Gateway Interface)라 불리는 표준 인터페이스를 제공하는 프레임워크로서, 비동기 싱글 프로세스로 작동한다.
- Uvicorn을 Gunicorn에서 기동해 멀티프로세스로 사용하는 것도 가능하다.
- Gunicorn은 WSGI (Web Server Gateway Interface)라 불리는 동기적인 애플리케이션 인터페이스를 제공한다.
-
Uvicorn을 Gunicorn에서 기동하면 ASGI의 비동기 처리와 WSGI의 멀티프로세스 조합이 가능하다.

- Pydantic은 파이썬의 타입 어노테이션을 이용한 데이터 관리 라이브러리이며, 런타임 레벨에서 타입 지정을 강제할 수 있다.
- Uvicorn은 ASGI (Asynchronous Server Gateway Interface)라 불리는 표준 인터페이스를 제공하는 프레임워크로서, 비동기 싱글 프로세스로 작동한다.
-
엔드포인트 (
app.py, 코드 4.1 참조)
-
API 리스트



Classifier: 모델을 사용해 추론을 실시하는 클래스-
load_model함수: 모델을 불러오는 역할을 한다.



-
추론기 서버는 Gunicorn으로 실행하여 WSGI와 ASGI가 가진 장점을 모두 얻는다.


-
추론기를 다음과 같이 도커를 통해 기동할 수 있다.


4.2.5 이점
- 추론기를 가볍고 신속하게 가동시킬 수 있다.
- 구성이 간단하기 때문에 장애 대응이나 복구가 간단하다.
4.2.6 검토사항
- 간단한 패턴이라 우려할 만한 점이 존재하지 않는다 → 복잡한 처리를 고려하지 않았다는 것 자체가 단점이 될 수 있다.
- 모델이 추가되면서 여러 개의 모델과 복잡한 워크플로를 통해 가치를 극대화하려는 것이 목적이라면 웹 싱글 패턴으로는 해결이 어렵다.
4.3 동기 추론 패턴
4.3.1 유스케이스
- 시스템의 워크플로에서 추론 결과가 나올 때까지 다음 단계로 진행이 되지 않는 경우.
- 워크플로가 추론 결과에 의존할 경우
4.3.2 해결하려는 과제
- 요청에 대해 동기적 또는 비동기적으로 추론 결과를 반환할 수 있다 → 각각 동기 추론 패턴과 비동기 추론 패턴이라고 부른다.
- 요청에 동기화하여 추론해 나가는 동기 추론 패턴을 알아본다.
4.3.3 아키텍처
- 클라이언트는 추론 요청을 전송한 후, 응답을 얻을 때까지 후속처리를 진행하지 않고 대기한다 (동기화).
- 추론 서버를 REST나 gRPC로 구성했을 경우, 동기 추론 패턴이 되는 경우가 많다.
- 동기 추론 패턴을 사용하면 워크플로를 순차적으로 만들 수 있고, 간단한 워크플로를 유지할 수 있어 구현과 운용이 간단하고 광범위하게 활용할 수 있다.
- 머신 러닝의 추론 프로세스 또한 동기적이다
- 데이터 입력 → 전처리 → 추론 → 후처리 → 출력까지 차례로 실행하는 구성이다.
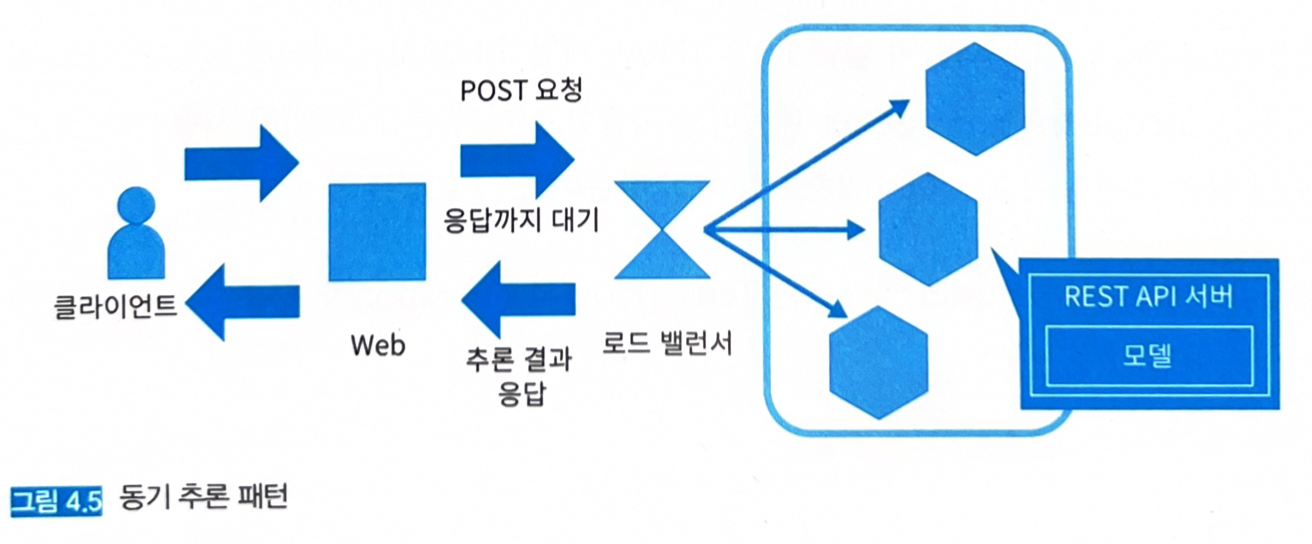
- 추론기의 지연으로 클라이언트를 기다리게 하는 사태가 발생할 수 있으므로, 그럴 땐 추론 프로세스를 고속화거나 비동기 추론 패턴을 활용하는 것이 좋다.
4.3.4 구현
-
Keras 모델에 전처리, 추론, 후처리를 포함하여 하나의
SavedModel로 구성하고, 도커 컨테이너로 TensorFlow Serving을 기동한다.



- 이처럼 추론에 필요한 모든 과정을 TensorFlow에 포함하여 서버 간 데이터 통신 횟수를 줄이고 효율적인 추론을 수행할 수 있다.
-
TensorFlow Serving의 도커 컨테이너 Dockerfile


-
컨테이너를 다음과 같은 명령으로 기동한다.

- TensorFlow Serving에서는 gRPC와 REST 엔드포인트를 표준으로 공개한다. (gRPC 포트 8500, REST 포트 8501)
-
추론 요청을 보내는 구현 예시:





-
고양이 이미지 파일을 추론 요청하는 커맨드


4.3.5 이점
- 간단한 구성으로 개발, 운용이 용이함.
- 추론이 완료될 때까지 클라이언트가 다음 처리로 이행하지 않기 때문에 순차적인 워크플로를 만들 수 있음.
4.3.6 검토사항
- 추론기의 응답이 느리면 사용자 경험이 나빠진다. → 클라이언트나 프록시에 타임아웃을 걸어두거나 추론기 타임아웃을 걸어놓는다.
4.4 비동기 추론 패턴
4.4.1 유스케이스
- 추론 요청 직후의 처리가 추론 결과에 의존하지 않는 워크플로일 경우.
- 클라이언트와 추론 결과의 출력처를 분리하고 싶은 경우.
- 추론에 시간이 걸려 클라이언트를 기다리게 하고 싶지 않은 경우.
4.4.2 해결하려는 과제
- 연산량이 커서 추론에 다소 시간이 걸리는 모델의 경우, 추론 결과를 기다리는 동안 후속 처리를 중지해야 하며, 속도가 느린 추론 처리는 결국 시스템 전체의 성능 저하로 이어지게 된다.
- 동기적으로 처리할 필요가 없는 워크플로
-
사진을 클라우드에 올리고 딥러닝으로 화질을 개선해서 제공하는 앱의 워크플로를 생각해보자.
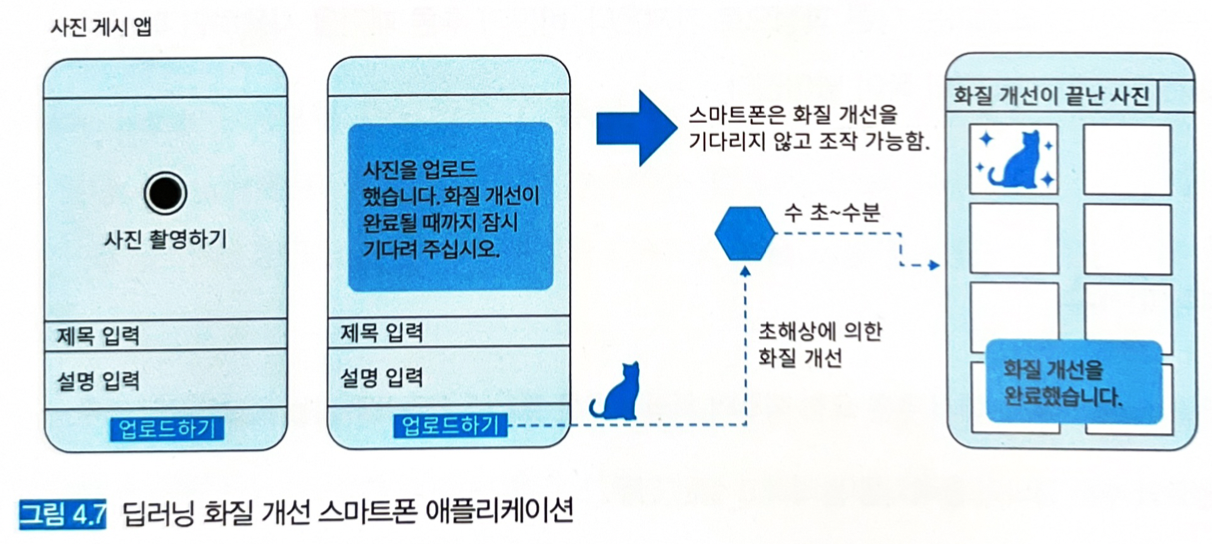
- 업로드 버튼을 누르고 난 다음의 처리를 비동기적으로 실시한다면, ‘사진을 업로드 했습니다. 화질 개선이 완료될 때까지 잠시 기다려주십시오.’와 같은 푸시 메시지를 보내 클라이언트의 조작을 멈추지 않고 화질 개선을 위한 시간을 확보할 수 있다.
- 추론이 완료된 후에 ‘화질 개선을 완료했습니다.’ 라는 팝업 메시지와 함께 파일 목록 화면에 개선된 이미지가 추가되어 있다면 사용자 경험이 그리 나쁘지 않을 것이다.
-
- 추론에 시간이 많이 소요되는 무거운 모델이라면 비동기적인 워크플로를 활용해 시스템 전체 성능을 유지할 것을 권장하는 추세다.
4.4.3 아키텍처
- 요청과 추론기 사이에 큐 (Kafka)나 캐시 (Rabbit MQ 또는 Redis Cache)를 배치해 추론 요청과 결과의 취득을 비동기화한다.
- 추론 결과는 큐나 캐시에 저장할 수도 있고 (그림 4.8), 다른 시스템이 출력할 수도 있다 (그림 4.9).
- 하지만 클라이언트에 추론을 반환하기 위한 커넥션이 필요하게 되고 시스템이 복잡해지기 때문에 권장하지 않는다.

4.4.4 구현
- 추론기에서는 모델을 TensorFlow Serving으로 기동한다.
- 엔드포인트에는 FastAPI로 프록시가 중개한다.
- 프록시는 추론 요청에 대해 작업 ID를 응답하고, 백그라운드에서 Redis에 요청 데이터를 등록한다.
- Redis에 등록된 요청 데이터는 배치로 TensorFlow Serving이 추론하고, 추론 결과는 다시 Redis로 등록된다.
-
클라이언트가 작업 ID를 프록시에 요청하면 추론이 완료되었을 때 그 결과를 얻게 된다.
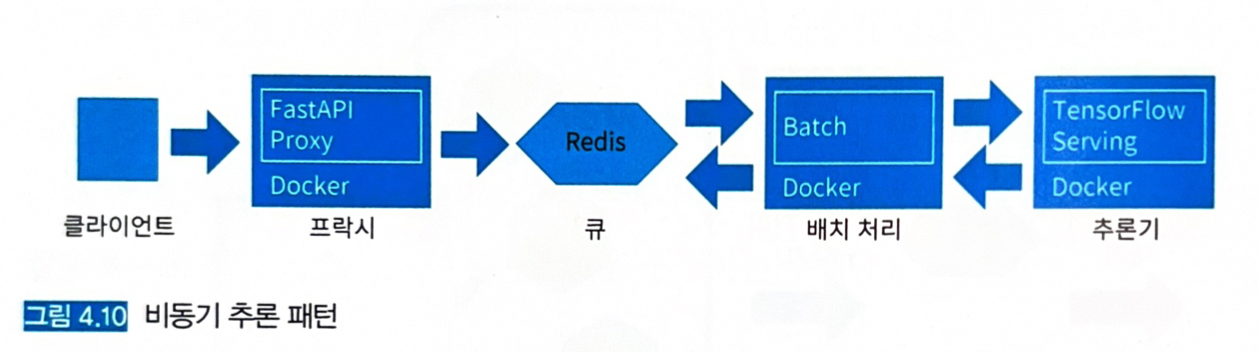



/predict요청 백그라운드에서는 Redis에 큐를 등록한다.- 큐에는 작업 ID를 키로 갖는 요청 이미지를 등록하고, 백그라운드 처리는 FastAPI의
BackgroundTasks를 사용하여 요청에 응답 후 실행하게 예약할 수 있다.
- 큐에는 작업 ID를 키로 갖는 요청 이미지를 등록하고, 백그라운드 처리는 FastAPI의
-
Redis로의 등록을
BackgroundTasks로 실행하는 코드:



- Redis에는
{작업 ID}_image라고 하는 키 (make_image_key)로 인코딩된 이미지 데이터가 등록된다.- 배치 서버에서 정기적으로 큐를 받아 추론하게 된다.
- 추론된 결과는 재차 Redis에 작업 ID를 키로 하여 등록된다.
-
배치 서버의 구현:



ProcessPoolExecutor로 워커 프로세스를 기동하고, 1초에 한 번 Redis를 폴링해서 추론 대기 중인 작업이 있으면 큐에서 꺼내 TensorFlow Serving에 요청하는 구성이다.-
도커 컴포즈로 기동해보자:


-
기동하고 요청해보자.


4.4.5 이점
- 클라이언트의 워크플로와 추론의 결합도를 낮출 수 있음.
- 추론의 지연이 긴 경우에도 클라이언트에 대한 악영향을 어느 정도 피할 수 있음.
4.4.6 검토사항
- 추론을 실행하는 타이밍이나 순서에 따라 아키텍처를 검토해야 한다.
- FIFO (First-In, First-Out) 방식으로 추론하는 경우, 클라이언트와 추론기의 중간에는 큐를 이용한다.
- 클라이언트는 요청 데이터를 큐에 추가한다 (enqueue)
- 추론기는 큐에서 데이터를 꺼낸다 (dequeue)
- 서버 장애 등으로 추론에 실패해서 재시도하기 위해서는 dequeue한 데이터를 큐로 되돌릴 필요가 있지만, 그렇지 못하는 사태가 발생하기도 하므로, 큐 방식으로 모든 데이터를 추론할 수 있다고는 할 수 없다.
- 순서에 구애되지 않는 경우 캐시를 이용한다.
- 클라이언트와 추론기 사이에 캐시 서버를 준비를 하고, 클라이언트로부터 요청 데이터를 캐시 서버에 등록한다.
- 추론기는 이 캐시 데이터를 가져와 추론하고, 추론 결과를 캐시에 등록한다.
- 그리고 추론하기 전이었던 상태의 데이터를 추론이 끝난 상태로 변경하는 워크플로를 취한다.
- 이런 방식이라면 추론에 실패하더라도 재시도할 수 있다.
- 재시도하는 경우, 재시도에 필요한 TTL이나 시도 횟수로 제한하는 것이 좋다.
- 데이터의 미비로 추론이 성공하지 못하는 경우, 데이터의 추론을 요청으로부터 5분 이내 (또는 재시도 3회 이내)로 하고, 초과한 경우는 요청을 파기하는 대처도 필요하다.
- 비동기 추론 패턴에서는 순서가 엄밀하게 보장되지 않기 때문에 데이터나 이벤트에 대한 추론 순서를 반드시 지켜야 하는 시계열 추론 시스템에서는 비동기 추론 패턴이 아닌 동기 추론 패턴을 선택하는 것을 권장한다.
4.5 배치 추론 패턴
4.5.1 유스케이스
- 실시간 또는 실시간에 준하는 추론을 할 필요가 없는 경우.
- 과거의 데이터를 정리해 추론하고 싶은 경우.
- 정기적으로 쌓인 데이터를 추론하고 싶은 경우.
4.5.2 해결하려는 과제
- 지금까지 축적된 데이터에 대해 의미를 부여하기 위해 배치 처리로 데이터를 추론하는 경우가 있다.
- 예를 들어 지난 3개월 동안의 데이터를 바탕으로 다음 달의 인력 배치를 계획하는 모델이라면 월말에 한 번만 추론을 해도 될 것이다.
- 실시간으로 추론할 필요가 없을 때나 정리된 데이터에 대해 추론하는 경우, 배치 처리로 추론 실행을 스케줄링할 수 있다.
4.5.3 아키텍처
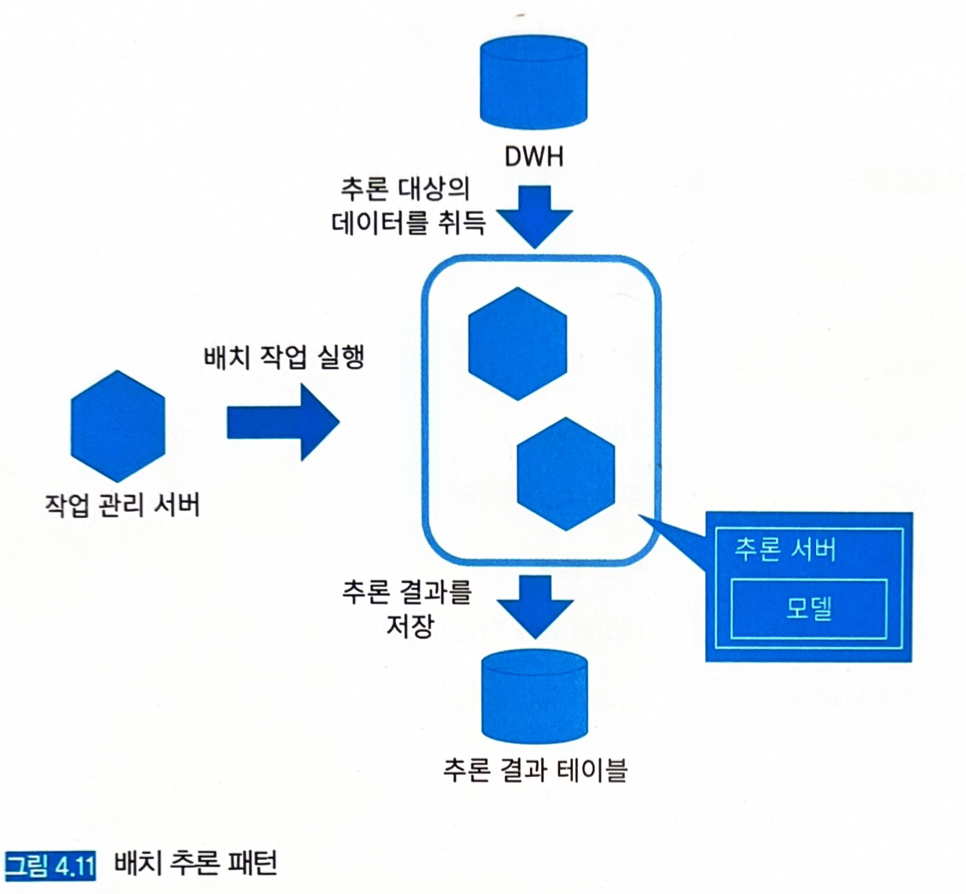
- 밀린 데이터를 야간 등 정기적으로 추론하고 결과를 저장한다. (반드시 야간에 실행할 필요는 없으며, 한 시간, 1개월 등 본인의 유스케이스에 따라 설정하면 된다)
-
추론기는 배치 작업을 수행할 때만 가동하고, 쿠버네티스로 서버의 시작/정지를 제어하면 인스턴스 비용도 아낄 수 있다.
4.5.4 구현
- 배치 작업을 정기적으로 실행하는 배치 서버가 데이터베이스에서 정기적으로 배치 대상 데이터를 취득하여 추론하고, 추론 결과를 데이터베이스에 등록하는 구성을 취한다.
- 리소스로 배치 서버와 데이터베이스 서버를 준비한다.
- 데이터베이스는 간단하게 MySQL을 사용하고 배치 서버부터는 SQL Alchemy라고 하는 파이썬의 ORM 라이브러리로 액세스한다.
- 먼저 데이터베이스를 정의한다.
-
SQL Alchemy와 Pydantic을 조합해 테이블의 스키마 정의와 CRUD를 파이썬 코드로 작성한다.



-
-
SQL Alchemy에서 테이블로 액세스하는 데이터 정의는 다음과 같다.


-
여기서 CRUD는 다음과 같다 (여기서는 데이터 취득, 등록, 업데이트 함수를 정의한다).



- 배치 서버에서는 이들을 정기적으로 호출하고, 추론 결과를 테이블의 PREDICTION 칼럼에 등록한다.
- 배치 작업의 내용은 다음과 같다.


- 여기서는 추론 결과가 등록되지 않은 데이터를 일괄적으로 취득해서 추론하고 테이블에 등록하고 있다.
- 이 작업을 정기적으로 수행하여 테이블에 쌓인 데이터에 추론 결과를 등록하는 구성이다.
- 쿠버네티스 CronJobs로 작업을 정기 실행하는 간단한 구성을 취한다.
- 예시에서는 MySQL도 간이로 쿠버네티스 클러스터에 Pods로 구축하고 있으나, 설명을 위한 간단한 구성이고 실제 환경에 구축하는 경우는 사용자명과 패스워드를 포함해서 수정해야 한다 (쿠버네티스 Secrets 등 활용).
-
쿠버네티스의 매니페스트는 다음과 같다. 한 시간에 한 번 쿠버네티스의 CronJobs가 실행되어 추론을 실행하는 구성이다.



4.5.5 이점
- 서버 리소스 관리를 유연하게 실시하여 비용 절감이 가능함.
- 시간적인 여유를 두고 스케줄링할 수 있다면 서버 장애 등으로 추론에 실패하더라도 재시도가 가능함.
4.5.6 검토사항
- 한 번의 배치 작업에서 추론의 대상으로 삼는 데이터의 범위를 정의해야 한다.
- 데이터 양에 따라 추론 시간이 달라지기 때문에 결과가 필요한 시점까지 추론이 완료될 수 있도록 데이터 양이나 실행 빈도를 조정해야 한다.
- 배치가 실패한 경우에 대한 방침을 정해 두는 것이 좋다.
- 전체 재시도: 모든 데이터에 대해 재시도한다 (데이터 간 상관관계가 추론에 영향을 미치는 경우).
- 일부 재시도: 실패한 데이터만 다시 추론한다.
- 방치: 재시도를 하지 않고, 다음 배치 작업에서 정리하여 추론한다 (실패한 데이터는 일절 추론하지 않는다).
- 정기 실행의 빈도가 낮은 경우, 클라우드 기반과 같이 정기적으로 업데이트가 발생하는 시스템이라면 배치 추론을 실행하려고 해도 시스템을 기동할 수 없는 사태가 일어나기도 한다.
- 다소 비용이 들더라도 정기적으로 소량의 데이터로 배치 추론을 실행한다면 1년에 한 번 배치 실행을 트러블슈팅하는 큰 비용을 절감할 수 있어 안정적인 시스템 운영이 가능하다.