[Study] 머신러닝 시스템 디자인 패턴 - Chapter 4 (part 2)
Chapter 4.6 - 4.10
4.6 전처리, 추론 패턴
4.6.1 유스케이스
- 머신러닝의 전처리와 추론에서 필요로 하는 라이브러리나 코드베이스, 미들웨어, 리소스가 크게 다를 경우.
- 전처리와 추론을 컨테이너 레벨로 분리해서 장애의 격리 및 가용성, 유지보수성이 향상될 경우.
4.6.2 해결하려는 과제
- 전처리에는 scikit-learn이나 OpenCV를 사용하고, 모델은 TensorFlow나 PyTorch로 구현하는 것이 일반적이다.
- 전처리는 데이터의 종류에 따라 다음과 같이 다양한 변환이 이뤄진다.
- 수치 데이터: 표준화 및 정규화
- 카테고리 데이터: one-hot encoding 및 결손치 보완
- 자연어 처리: 형태소 분석, Bag of words, Ngram
- 이미지: 리사이즈, 픽셀의 정규화
4.6.3 아키텍처
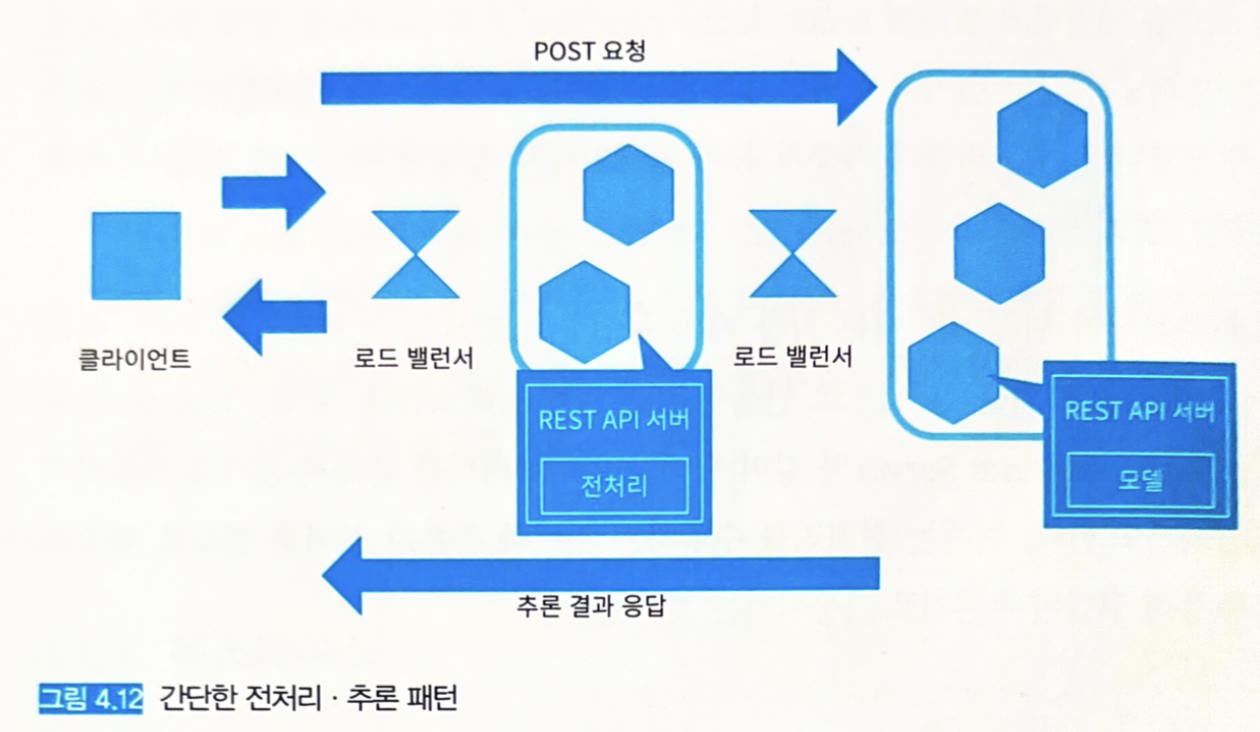
- 그림 4.12: 전처리 추론 패턴
- 클라이언트에서 전처리 서버로 요청을 보내면 전처리 서버에서 데이터를 변환한다.
- 이후, 추론기에 요청을 보내 추론 결과를 취득하고 클라이언트로 응답한다.
- 전처리 서버와 추론기를 분할하기 위해서는 각각의 리소스 튜닝이나 상호 네트워크 설계, 버저닝이 필요하다.
- 웹 싱글 패턴보다 구성은 복잡하지만, 효율적인 리소스의 활용이나 별도의 개발, 그리고 장애를 격리할 수 있다.
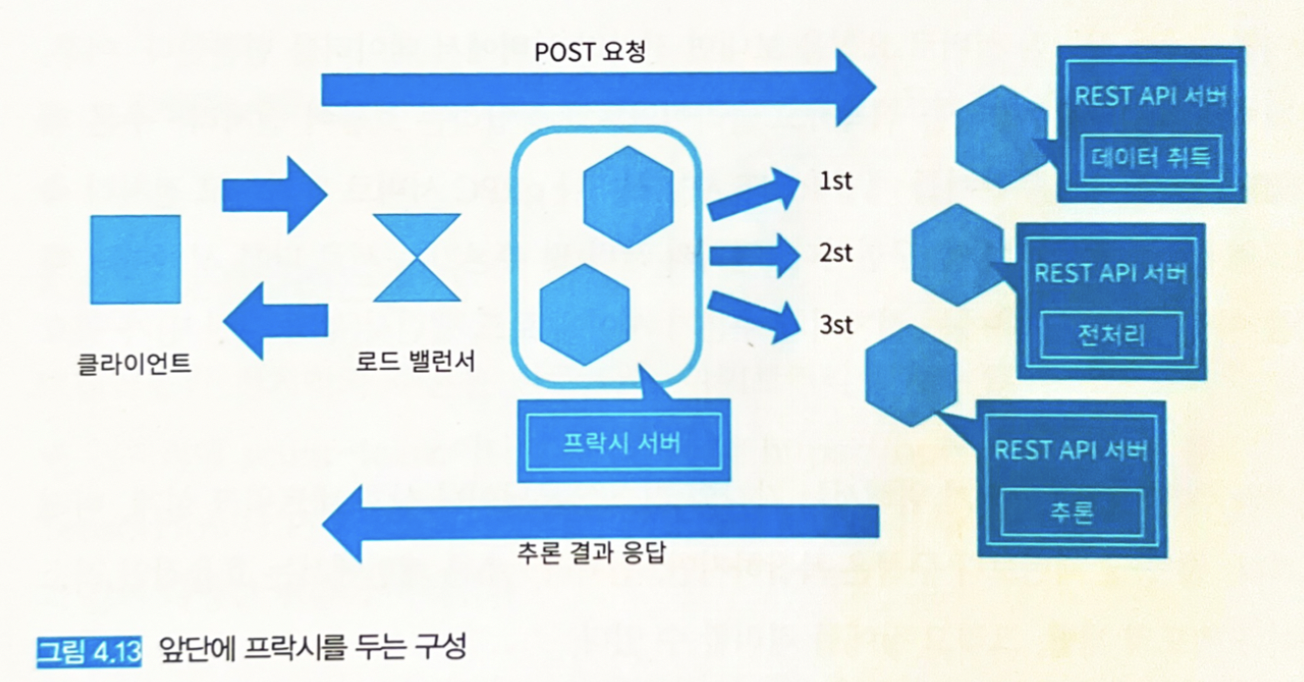
- 그림 4.13
- 앞단에 프록시를 배치하여 전처리와 추론을 마이크로서비스화하는 패턴도 가능하다.
- 데이터 취득 서버, 전처리 서버, 추론 서버를 독립적인 라이브러리나 코드베이스, 리소스로 개발할 수 있지만, 컴포넌트가 늘어나기 때문에 버전 관리가 어려워질 수 있다.
4.6.4 구현
-
전처리 서버와 추론 서버를 따로 구축한다.
-
코드 4.17: 전처리와 모델 준비







-
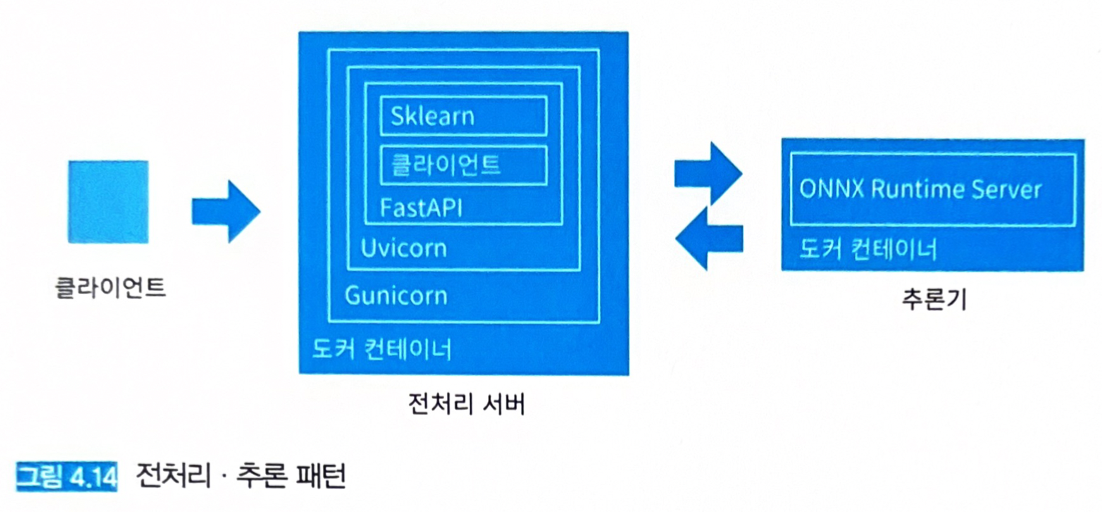
전처리 서버는 FastAPI를 사용해 REST API 서버로 구축한다. FastAPI의 엔드포인트는 이미지가 입력되는 것을 제외하면 웹 싱글 패턴과 동일하다.


- 전처리 서버에서는
/predict로의 요청에 대해Classifier클래스에 정의한predict함수를 호출하여 전처리를 실행하고, 추론 서버에 gRPC로 추론 요청을 보낸다.- 이 시점에서 전처리 서버는 추론 서버에 대해 gRPC 클라이언트로서 가동되고 있다.
- 전처리 서버는 추론 결과를
SoftmaxTransformer를 통해 확률값으로 변환하고 클라이언트에 응답하는 흐름을 취한다. (이에 대한 구현은 코드 4.19와 같다.)




-
코드 4.19의 전처리 서버에서는 추론 서버에 대해 gRPC로 요청을 보내고 있다.
- 추론 서버는 ONNX Runtime Server로 기동한다.
- TensorFlow Serving과 마찬가지로 ONNX 형식의 모델 파일을 열고 REST API 겸 gRPC 서버로서 기동할 수 있다.
-
ONNX Runtime Server는
mcr.microsoft.com/onnxruntime/server:latest이미지를 사용하여 코드 4.20과 같은 스크립트로 기동할 수 있다.

-
전처리 서버와 추론 서버는 도커 컴포즈로 기동한다. 도커 컴포즈 구성은 코드 4.21과 같다.
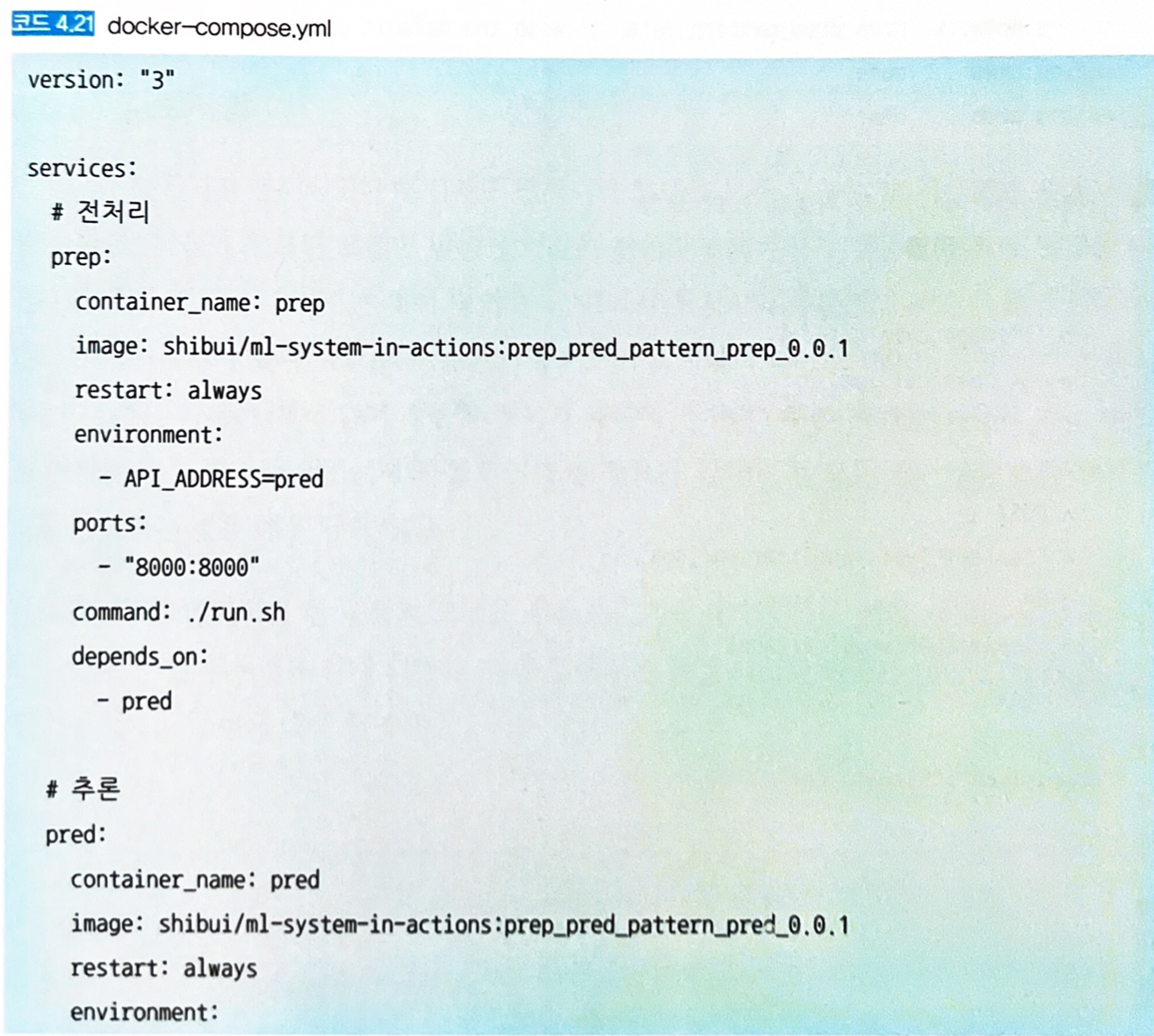

-
도커 컴포즈로 기동한 전처리 서버에 JPEG 고양이 이미지 파일의 분류를 요청한다.

- 전처리, 추론 패턴에서 지금까지 패턴에는 없었던 파이썬을 사용한 처리 계열과 ONNX Runtime, TensorFlow Serving을 조합한 추론기의 구축이 가능했다.
- 학습에 사용한 라이브러리를 지우너하는 전용 런타임으로 추론기를 구성할 수 있다면 번거로움을 덜 수 있겠지만, 모든 전처리나 후처리가 런타임으로 지원되는 것은 아니기 때문에 일부를 파이썬으로 실행하고 추론만을 런타임으로 가동시키는 아키텍처가 되는 것이다.
4.7 직렬 마이크로서비스 패턴
4.7.1 유스케이스
- 여러 개의 추론기로 구성되는 시스템에서 추론기 사이의 의존성이 명확한 경우.
- 여러 개의 추론기로 구성되는 시스템에서 추론의 실행 순서가 정해져 있는 경우.
4.7.2 해결하려는 과제
- 하나의 입력 데이터에 대해 여러 추론기를 조합하여 하나의 추론을 완성하는 워크플로도 있다.
- 예를 들어 고양이가 찍힌 사진에서 고양이의 위치와 품종을 분류하고 삼색 고양이라면 일본식으로, 서양 품종 고양이라면 서양식으로 스타일을 변환하는 서비스를 만든다고 해보자.
- 3개의 추론: 사진 내의 고양이 객체 인식 → 바운딩 박스 내부에 대해 이미지 분류를 실시 → 스타일 변환 (Neural style transfer)
- 만약 모든 추론 모델을 동일한 추론기에 포함시킨다면 추론기의 사이즈가 방대해지고 효율성이 떨어진다.
- 추론 모델과 추론기를 일대일로 구성하는 것이 개발과 운용 측면에서 매우 유연하다.
4.7.3 아키텍처
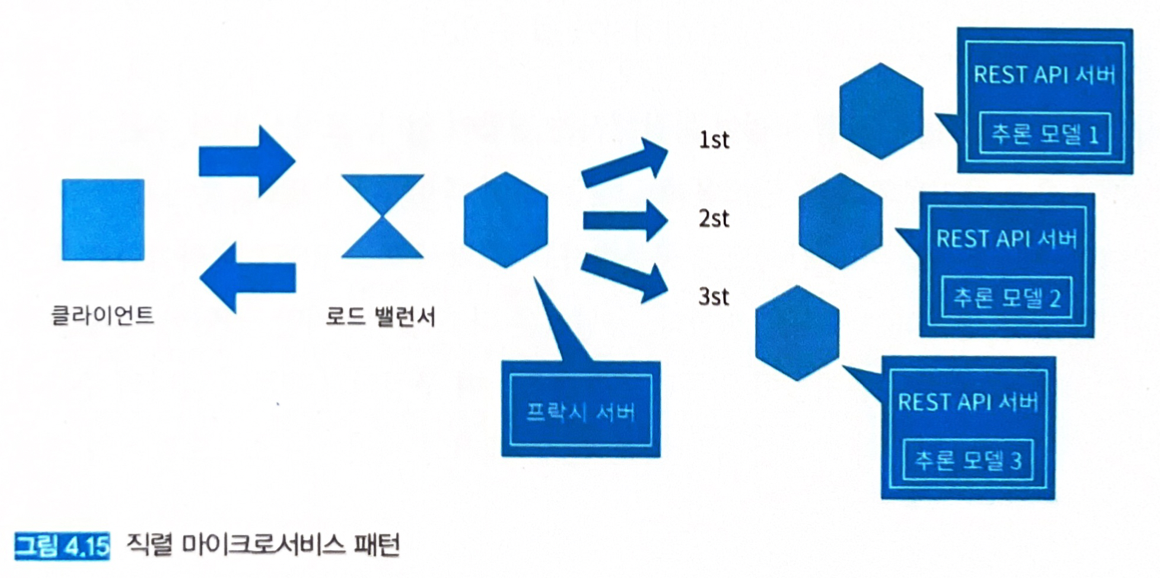
- 의존관계가 있는 여러 개의 추론 모델을 각각의 추론기로 배치하여 추론을 하나로 이어 붙인 워크플로를 실현한다.
- 각 추론기는 마이크로서비스로 배치하고, 클라이언트와 추론기 사이에는 프록시를 배치한다.
- 프록시에서 요청을 보내는 추론기의 엔드포인트는 환경변수로 설정할 수 있게 해 두면 운용상 편리하다.
- 프록시에서 모든 요청을 제어할 수 있어 요청 처리 경로를 유연하게 바꿀 수 있다.
- 예를 들어 고양이 이미지에서 객체 인식에 문제가 있는 경우, 객체 인식을 건너 뛰고 이미지 분류를 진행하는 흐름도 가능하다. (결과는 예상과 다르겠지만, 최소한 응답이라도 가능하게 해주는 것이 유익한 상황일 수도 있다).
- 특정 추론기에서 에러가 발생해도 전체를 멈추지 않는 구성을 이루기 위해 프록시를 두는 것이다.
4.7.4 구현
- 전처리, 추론 패턴과 거의 동일하기 때문에 생략.
4.8 병렬 마이크로서비스 패턴
4.8.1 유스케이스
- 의존관계가 없는 여러 개의 추론을 병렬로 실행할 경우.
- 여러 개의 추론 결과를 마지막으로 집계하는 워크플로일 경우.
- 하나의 데이터에 대해 여러 개의 추론 결과를 필요로 할 경우.
4.8.2 해결하려는 과제
- 하나의 데이터에 대해 분류와 회귀로 서로 다른 추론 결과를 얻어 놓고, 각 결과를 다른 목적으로 사용하고 싶은 경우가 있다.
- 예를 들어 웹 서비스의 동일한 이벤트 로그에 대해 분류 (위반 행동 검지)나 회귀 (구매 예측) 문제로 접근할 수 있다.
- 이진 분류를 여러 번 실행한 결과를 집계해서 하나의 통합된 추론 결과로 만들기도 한다.
- 예를 들어 이벤트 로그에 대해 서로 다른 몇 가지의 위반 행동을 검지하고 싶은 경우에도 개별적인 위반 행동에 대한 검지 모델을 이진 분류로 개발해 병렬로 추론하는 방법도 있다.
4.8.3 아키텍처
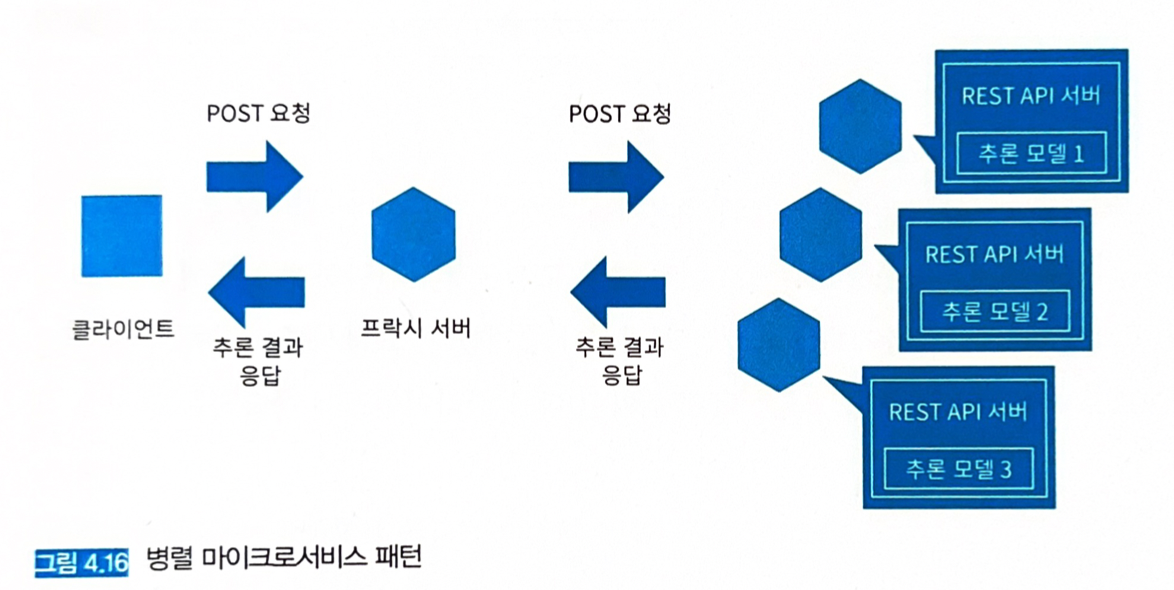
- 의존 관계가 없는 여러 개의 추론 모델을 병행하여 실행하고, 각 추론기로 동시에 추론 요청을 전송하여 서로 다른 여러 개의 추론 결과를 얻는다. 중간에 프록시를 두어 데이터의 취득이나 추론 결과를 집약하는 태스크를 넣을 수 있다.
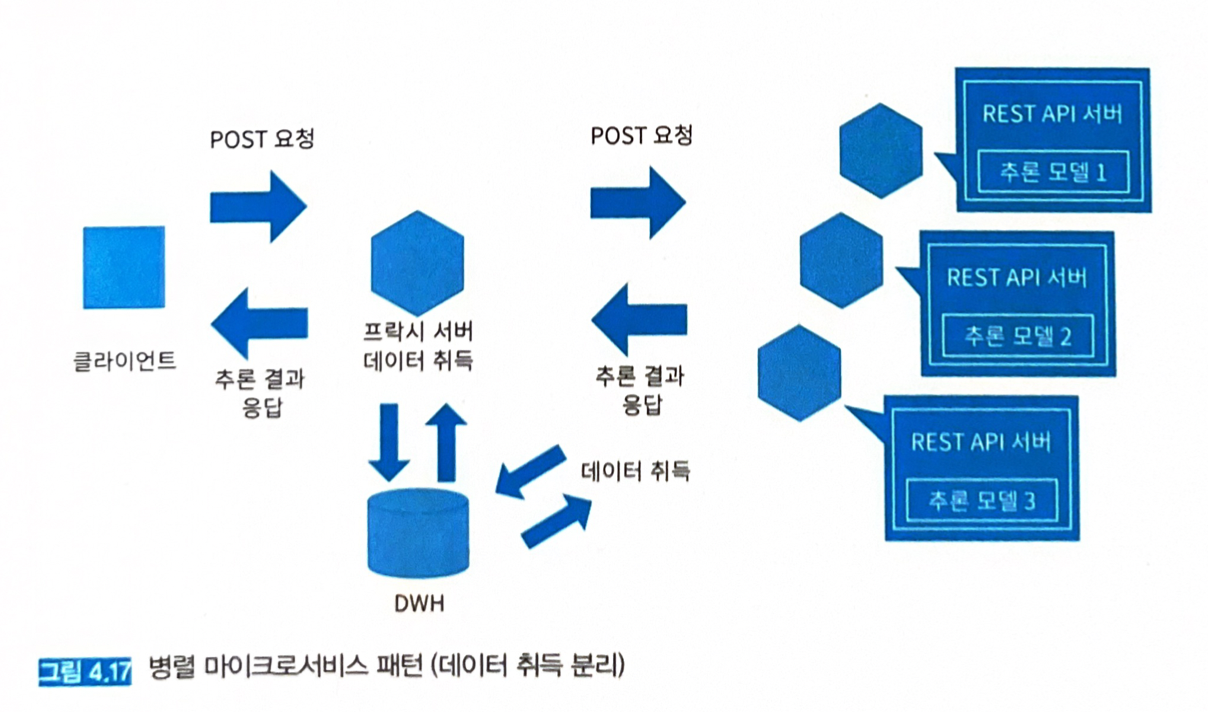
- 추론을 위한 입력 데이터는 프록시에서 일괄 수집할 수도 있지만, 각 추론 서버에서 취득하는 방법도 있다.
- 전자는 DWH나 스토리지의 액세스 횟수를 줄여 오버헤드를 줄일 수 있다는 것이 장점이다.
- 후자는 각 모델이 필요한 데이터를 취득해 복잡한 워크플로를 실현할 수 있다는 장점이 있다.
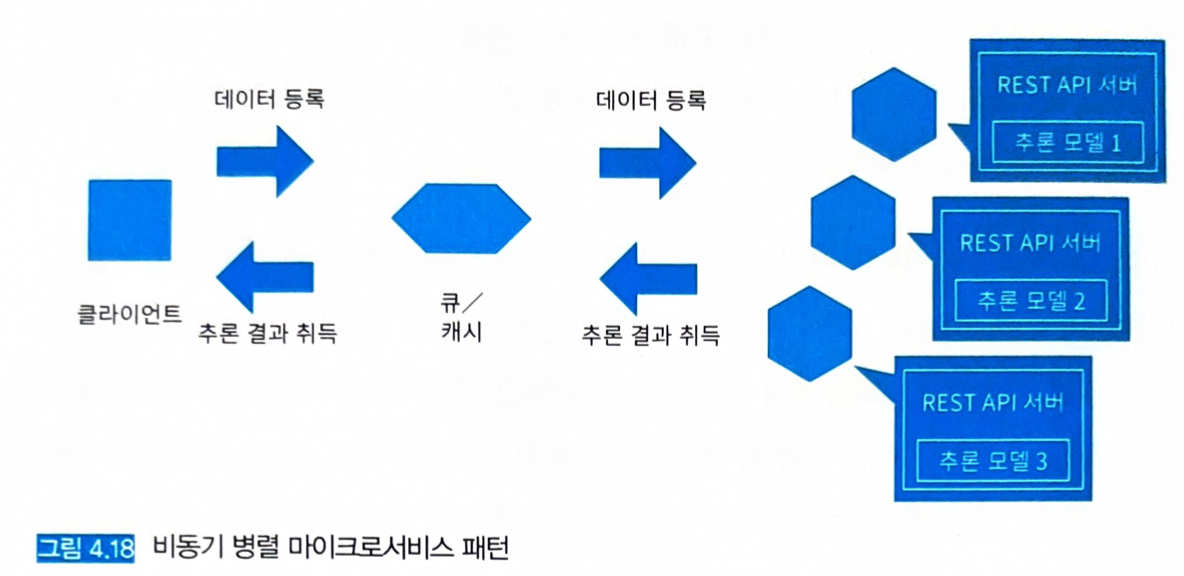
- 용도에 따라 동기적/비동기적으로 실행하는 방침을 정해야 한다.
- 동기적: 모든 추론을 취득한 후 결과를 집계. (모든 추론 결과를 얻을 때까지 후속 워크플로가 진행되지 않는다)
- 비동기적: 추론을 얻는 즉시 액션을 취하는 경우.
4.8.4 구현
- 붓꽃 데이터셋의 클래스 (setosa, versicolor, virginica)별로 이진 분류 모델 3개를 만들어 서로 다른 추론기로 가동시킨다.
- 프록시를 경유해서 전 추론기에 추론을 요청하고, 결과들을 프록시에서 모은 다음 클라이언트에 응답한다.
-
프록시 엔드포인트 구현 (코드 4.22)



/predict와/predict/label은 요청된 데이터에 대한 추론으로, 모두 httpx로 추론기에 대해 POST 요청을 수행하고 추론 결과를 얻는 구성이다./predict엔드포인트는 각 추론기의 이진 분류 결과를 응답한다./predict/label엔드포인트에서는 각 추론기가 수행한 이진 분류 결과를 모으고, 가장 확률이 높은 클래스를 응답한다.- 추론기는 웹 싱글 패턴과 같아서 생략.
-
프록시 + 추론기 실행 (도커 컴포즈)



- 프록시를 9000번 포트로 기동하고 각 추론기는 8000~8002번 포트로 공개한다.
-
클라이언트는 프록시에 결과를 요청하고 모든 추론기로부터 집약된 추론 결과를 얻을 수 있다.


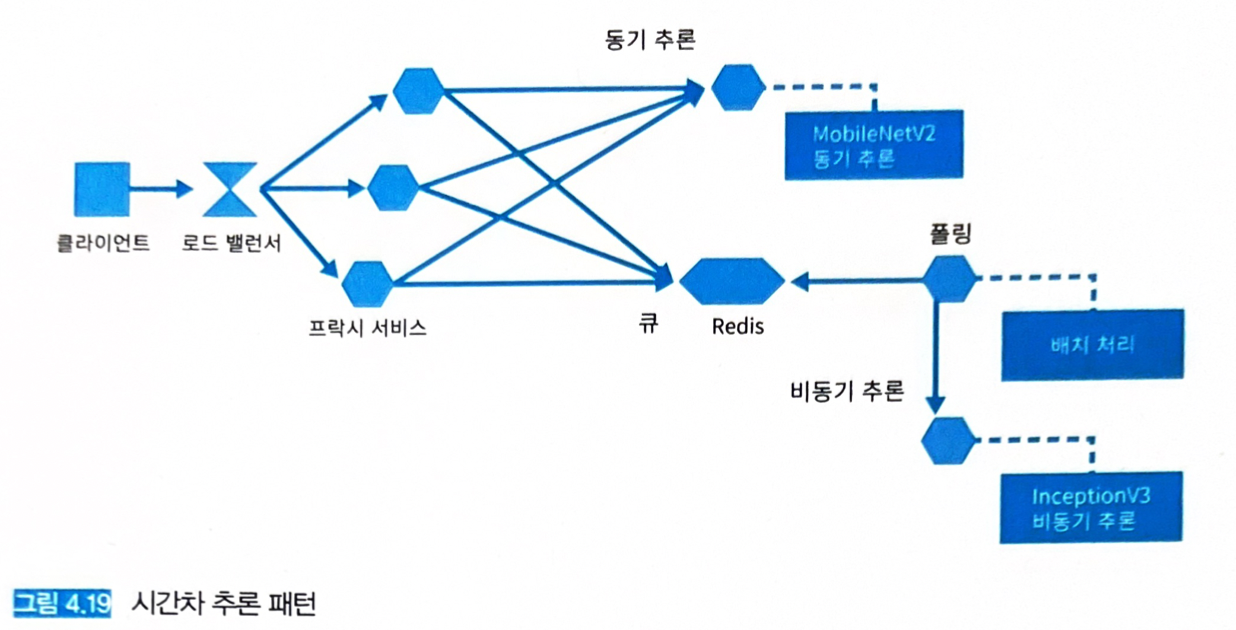
4.9 시간차 추론 패턴
4.9.1 유스케이스
- 인터랙티브한 애플리케이션에 추론기를 삽입할 경우.
- 응답이 빠른 추론기와 느린 추론기를 조합한 워크플로를 만들고 싶은 경우.
4.9.2 해결하려는 과제
- 여러 추론기를 조합할 때 문제는 추론기 간의 지연 시간에 차이가 있다는 것이다.
- 시간차 추론 패턴에서는 빠른 추론기를 동기적인 추론과 응답에 활용하고, 느린 추론기는 비동기적으로 추론해 두었다가 추론이 완료되면 결과를 클라이언트에 반영하는 전략을 세울 수 있다.
4.9.3 아키텍처
- 여러 단계로 나눠 클라이언트에 응답할 경우에 유효하다.
- 정형 데이터를 다루는 모델은 추론이 빠르고, 이미지나 텍스트 같은 비정형 데이터를 다루면 느려지는 경향이 있다.
- 앱이 인터랙티브하게 사용된다면…
- 빠른 추론기로 즉시 추론 결과를 응답한 후에 사용자가 서비스를 사용하는 동안 더 좋은 추론 결과를 다음 화면 (또는 스크롤한 화면)에 준비해 두는 라이프 사이클을 생각할 수 있다.
- 두 종류의 추론기 (빠르고 동기적, 무겁고 비동기적)를 배치한다.
- 동기적이고 빠른 추론기는 신속 응답을 위해 REST API나 gRPC를 사용하면 좋다.
- 비동기적이고 무거운 추론기는 처리 시간이 발생하기 때문에 메시징이나 큐를 중개한다.
4.9.4 구현
- 이미지 분류를 위해 다음 모델을 사용한다.
- MobileNetV2 (동기적)
- InceptionV3 (비동기적)
- 프록시에서는 MobileNetV2로의 추론 요청에 대해 동기적으로 응답한 후 Redis에 요청된 이미지를 큐에 추가하는 구성을 취한다.
- 배치 서버가 Redis 큐를 폴링하고, 처리 못한 데이터가 있으면 큐에서 꺼내 InceptionV3에 요청을 보낸다.
- 추론기와 배치 서버는 비동기 추론 패턴과 같아 생략.
- 프록시는 병렬 마이크로서비스 패턴과 유사하나, Redis에 데이터를 등록하는 과정이 추가된다.
- FastAPI로 웹 API를 기동하고, MobileNetV2 추론기에 대한 요청은 gRPC 클라이언트로 전송하며, InceptionV3에서 추론하기 위한 큐는 Redis에 등록한다.
- Redis 등록은 FastAPI BackgroundTasks를 사용하며, 동기적으로 응답한 후에 실시되기 때문에 응답이 방해받는 일은 없다.



- 프록시의 API는 비동기 추론 패턴과 동일하다.
/predict가 클라이언트로부터 요청 데이터를 받아들이는 엔드포인트다.- 비동기 추론의 결과는
/job/{job_id}엔드포인트에서 취득한다.
-
도커 컴포트 구성:



-
각 리소스를 기동해서 고양이 이미지 파일을 요청해 보자.


4.10 추론 캐시 패턴
4.10.1 유스케이스
- 동일 데이터에 대해 추론 요청이 발생함과 동시에 그 데이터를 식별할 수 있는 경우.
- 동일 데이터에 대해 동일한 추론 결과를 응답할 수 있는 경우.
- 입력 데이터를 검색할 수 있는 경우.
- 추론의 지연을 단축하고 싶은 경우.
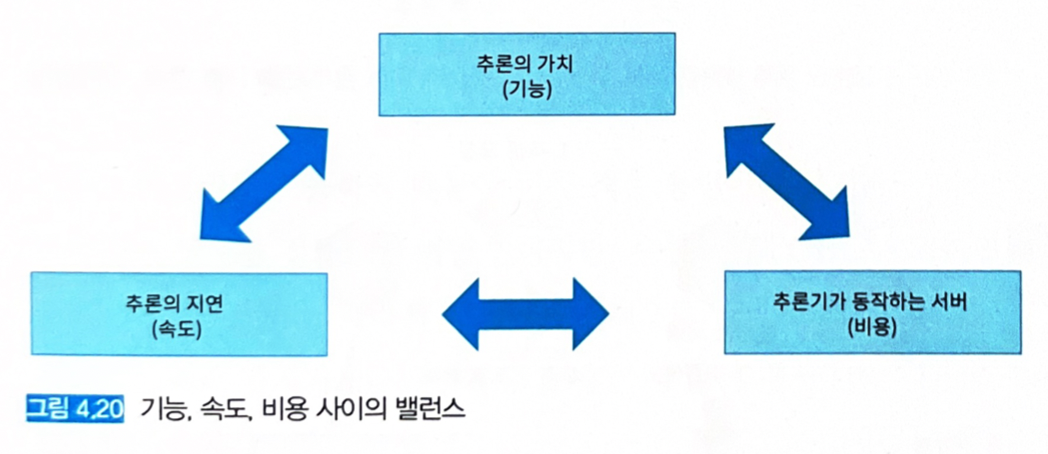
- 캐시를 이용해 비용과 속도에 관한 문제를 개선한다.
- 추론 결과를 캐시해두고, 동일한 입력 데이터가 요청된 경우에는 캐시해 둔 추론 결과를 응답한다.
- 캐시 타이밍:
- 사전에 배치 추론을 실행하고 캐시함.
- 추론 시에 캐시함.
- 1과 2의 조합.
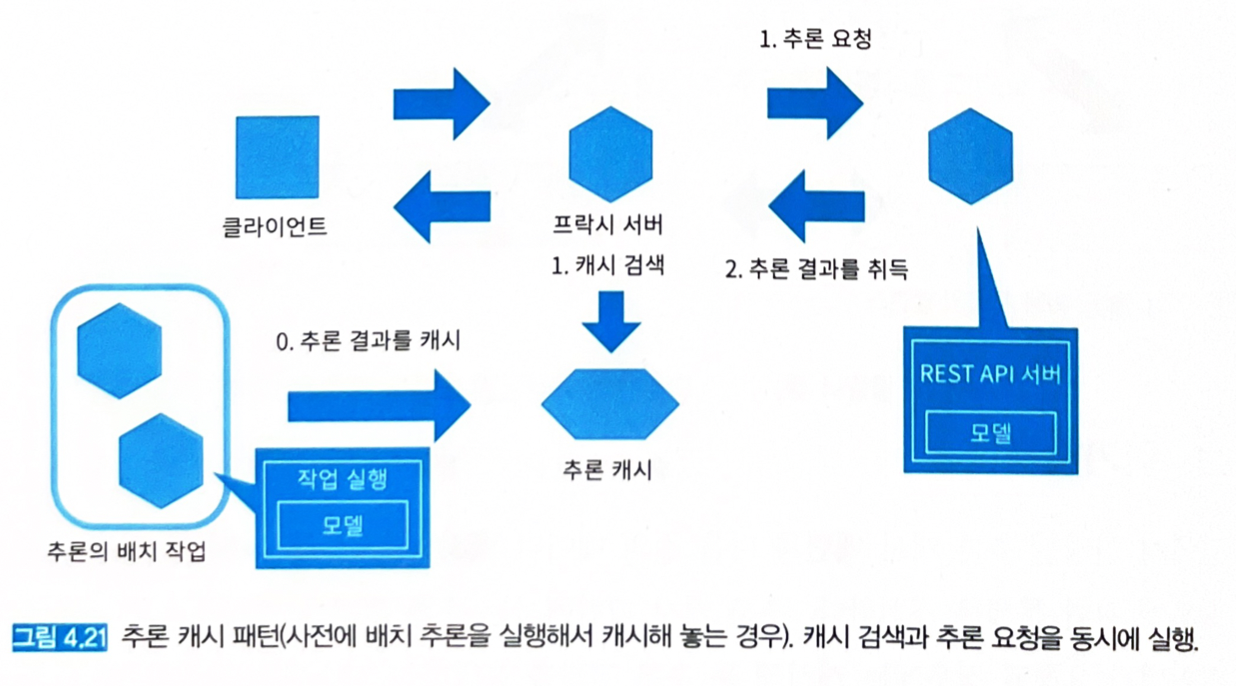
- 사전에 배치 추론해 놓는 경우는 캐시 대상이 되는 입력 데이터를 사전에 예측할 수 있어야 한다.
- 검색 시스템이라면 검색 빈도가 높은 상위 1,000건 등을 캐시해 두는 경우.
- 추론 타이밍은 요건에 따라 달라지나, 추론 결과가 시간에 따라 변하지 않는다면 추론기 릴리즈 타이밍에 캐시를 해두는 것이 좋다.
- 문제점: 캐시 대상 데이터가 요청되지 않으면 캐시가 소용이 없다. 높은 빈도로 요청되는 입력 데이터가 변하지 않아야 한다.
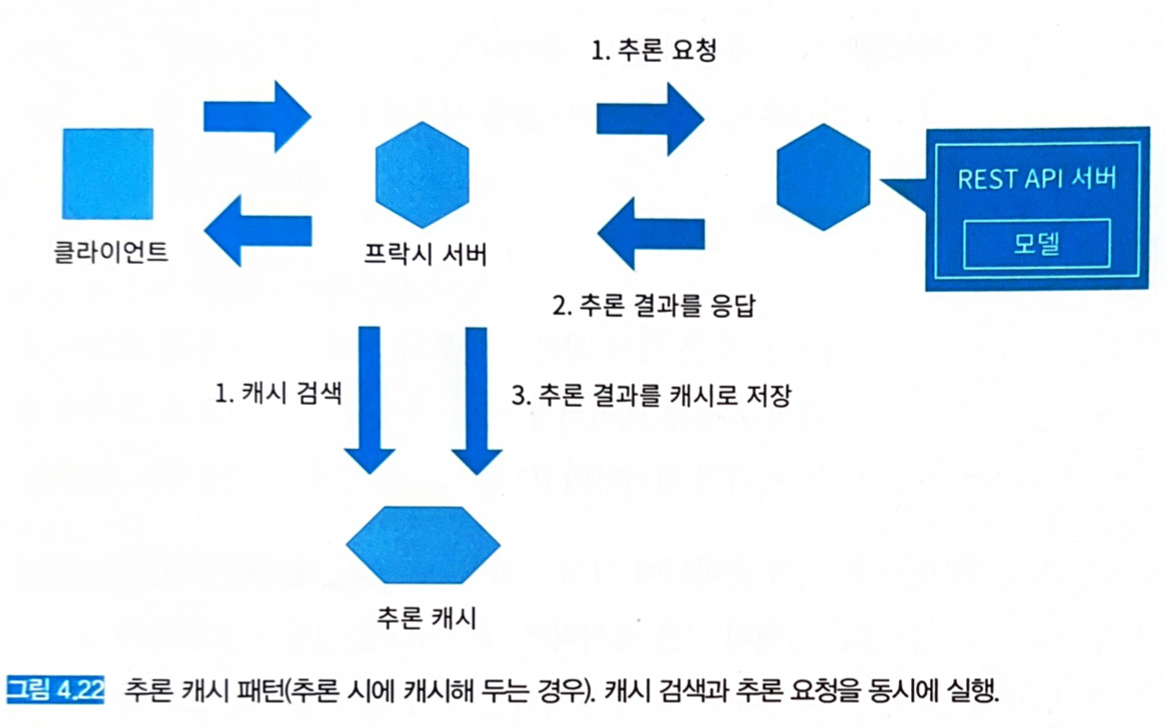
- 추론 시에 캐시하는 경우는 추론 후에 캐시 서버에 등록하는 처리가 필요하다.
- 추론마다 캐시를 등록하기 때문에 중복 데이터가 적을 경우 캐시 양이 증가할 수 있는 문제가 생긴다.
- 실용화하기 위해서는 1번과 2번을 조합해서 운용하는 것이 좋다.
- 1번처럼 사전에 캐시 데이터를 작성해 두고, 2번처럼 1번에서 캐시되지 않은 데이터를 추가해 나가는 방식이다.
- 캐시 검색 타이밍에도 선택지가 있다.
- 추론기에 추론을 요청하기 전에
- 추론기에 추론을 요청함과 동시에
- 1번의 경우에는 캐시 히트 수만큼 추론기의 부하를 줄일 수 있다. 캐시 적중률이 높으면 자원 효율이 좋으나 캐시 미스가 많으면 검색 시간이 추론 지연에 더해지므로, 성능 저하로 이어질 수 있다.
- 2번의 경우, 캐시 히트하면 추론 요청을 바로 취소하고 응답하며, 캐시 히트하지 않으면 추론 결과를 기다렸다가 응답한다. 모든 요청을 일단 추론기로 보내기 때문에 추론기 자원을 모두 사용해야 하지만 성능 저하 우려는 없다.
- 1번처럼 사전에 캐시 데이터를 작성해 두고, 2번처럼 1번에서 캐시되지 않은 데이터를 추가해 나가는 방식이다.
- 캐시 검색 타이밍에도 선택지가 있다.
4.10.4 구현
- 추론 요청을 받는 웹 API 서버로 FastAPI, 추론 결과를 캐시해 두는 환경으로는 Redis를 사용한다.
- 웹 API 서버는 Redis에서 데이터 ID를 검색한 후, 캐시 히트 시에는 그대로 응답한다.
-
캐시 히트 실패 시 ResNet50 ONNX Runtime Server로부터 추론 결과를 취득하고 클라이언트에 응답한 후 추론 결과를 Redis에 등록한다.
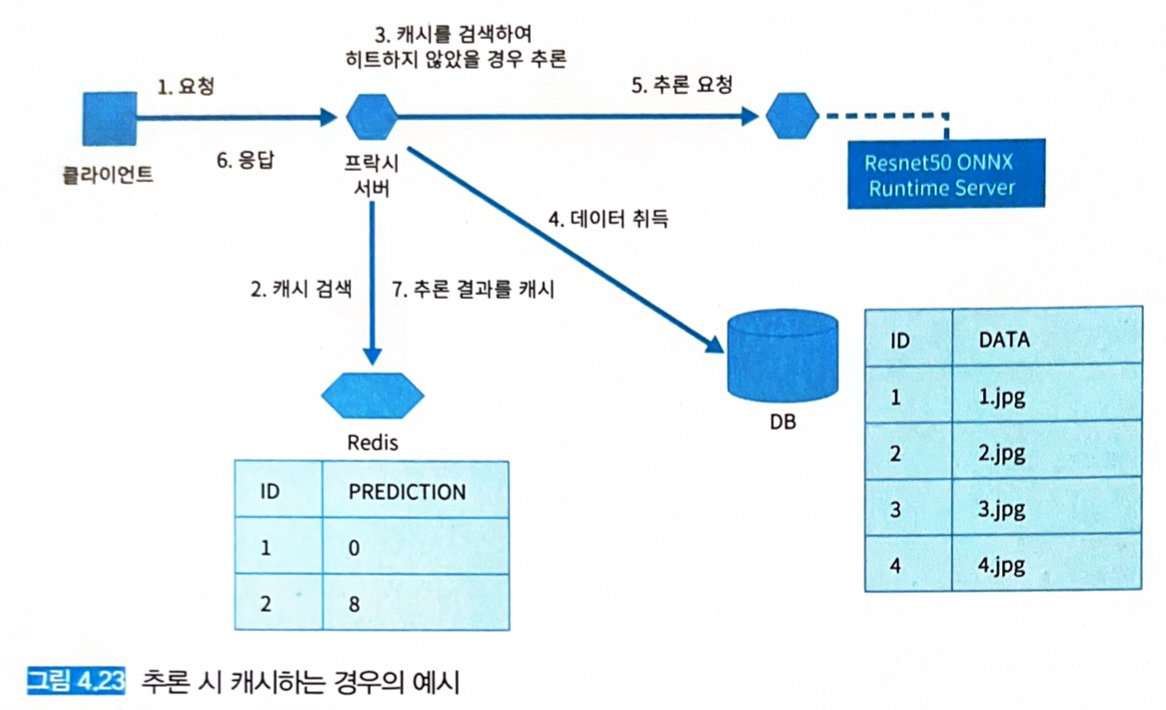
-
API 엔드포인트


-
캐시의 등록과 검색은 Classifier 클래스의 predict 함수로 실행한다.





-
도커 컴포즈 기동

