[Study] 머신러닝 시스템 디자인 패턴 - Chapter 4 (part 3)
Chapter 4.11 - 4.15
4.11 데이터 캐시 패턴
4.11.1 유스케이스
- 동일한 데이터의 추론 요청이 발생하고, 동시에 그 데이터가 동일한 것으로 식별이 가능한 경우.
- 동일한 데이터를 반복적으로 처리할 경우.
- 입력 데이터를 캐시 등으로 검색할 수 있는 경우.
- 데이터를 매우 빠르게 처리하고 싶은 경우.
4.11.2 해결하려는 과제
- 추론 결과만 캐시할 수 있는 것이 아니다. → 데이터 캐시 패턴에서는 입력 데이터나 전처리가 이뤄진 데이터도 캐시할 수 있다.
- 예를 들어 이미지나 텍스트 데이터에 대한 추론 요청
- 이미지를 데이터베이스로 관리한다면 매 요청마다 이미지를 송신하는 것보다 데이터베이스상의 ID로 통신하는 것이 효율적이다.
- 전처리 후의 데이터를 캐시하는 것도 가능하다.
- 나아가 딥러닝으로 입력 데이터의 특징을 뉴럴 네트워크로 추출하여 추론하는 경우, 뉴럴 네트워크 추출이 병목이 될 수 있으므로 추출한 특징 데이터를 캐시해두면 효과적이다.
4.11.3 아키텍처
- 데이터 캐시 타이밍은 추론 캐시 패턴과 마찬가지.
-
사전에 배치로 (그림 4.25)
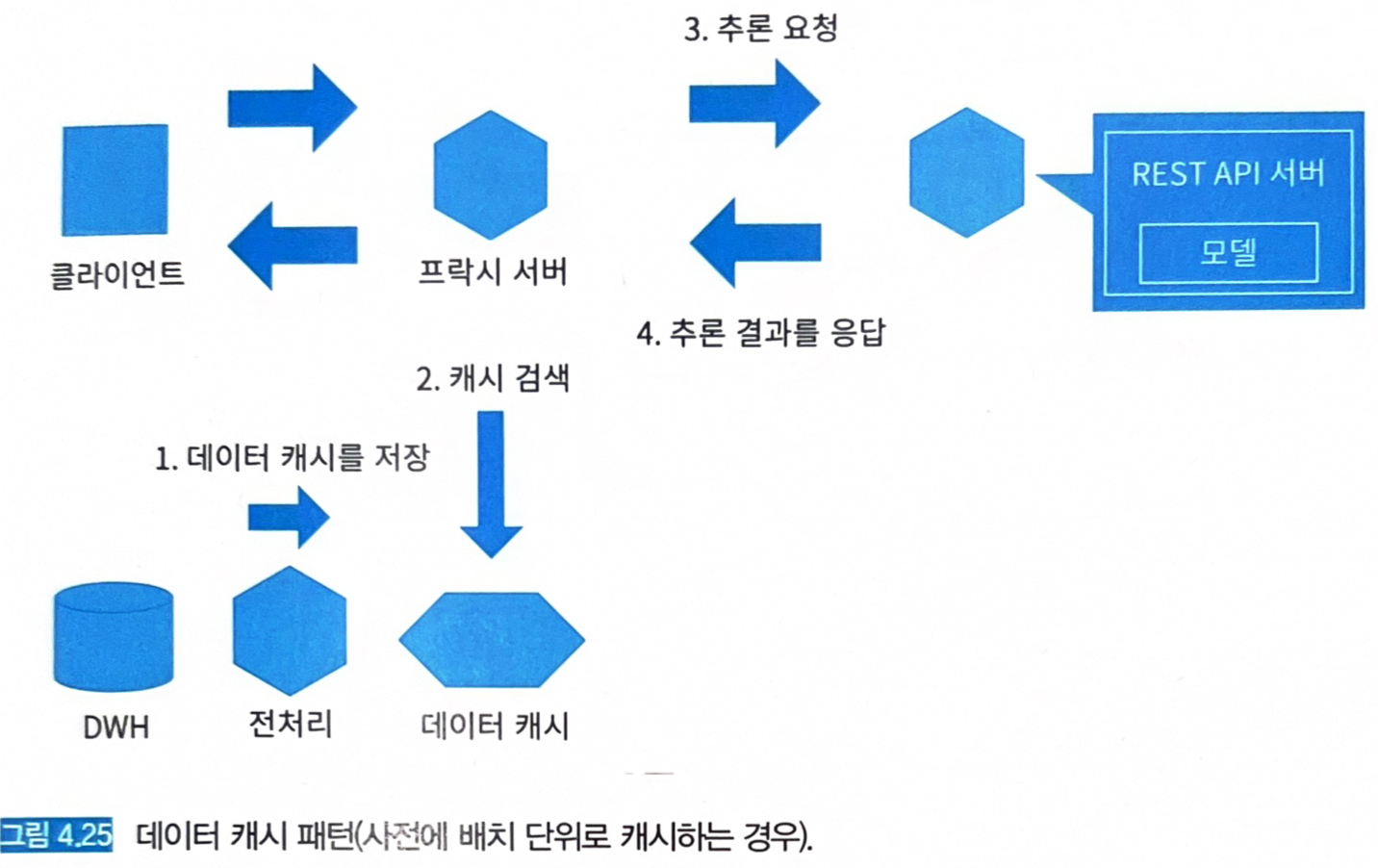
- 용량이 넉넉할 때 도입 수월함.
- Key: 데이터 ID
- Value: 데이터 자체, 혹은 추출된 특징 데이터.
- 비용과 용량 초과에 대비하여 캐시 클리어 방침이 필요하다. (용량 큰 데이터에 대한 정기적 캐시 클리어 & 갱신 필요)
- 용량이 넉넉할 때 도입 수월함.
-
추론 요청 시에 (그림 4.24)
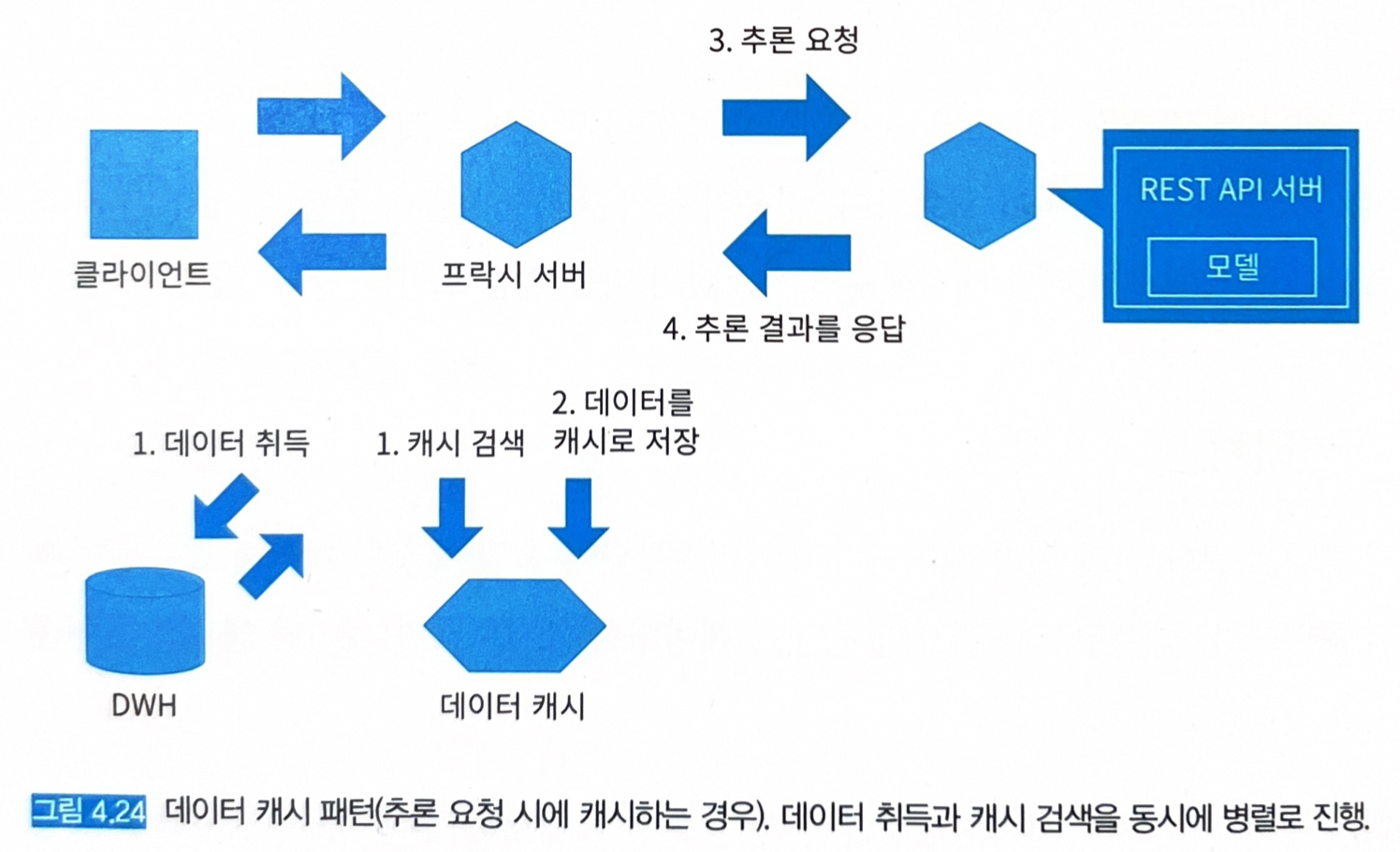
-
1과 2의 조합
-
4.11.4 구현
- 추론 캐시 패턴과 구현 방식이 유사하다.
- 차이가 있다면 캐시하는 타이밍과 그 대상이다.
- 추론 캐시 패턴은 추론 이후에 추론 결과를 캐시.
- 데이터 캐시 패턴은 데이터를 취득하는 시점이나 전처리를 수행하는 시점에 데이터를 캐시.
- 변환된 데이터를 다시 사용하는 시스템을 구축하는 경우에 유효한 패턴이 된다.
- 추론 결과의 캐싱은 모델에 의존하기 때문에 모델 변경 시 추론 결과가 달라진다.
- 입력 데이터 전처리는 모델 간 공통화가 가능하므로 이 데이터를 캐시해 두면 재이용이 가능하다 (그림 4.26)
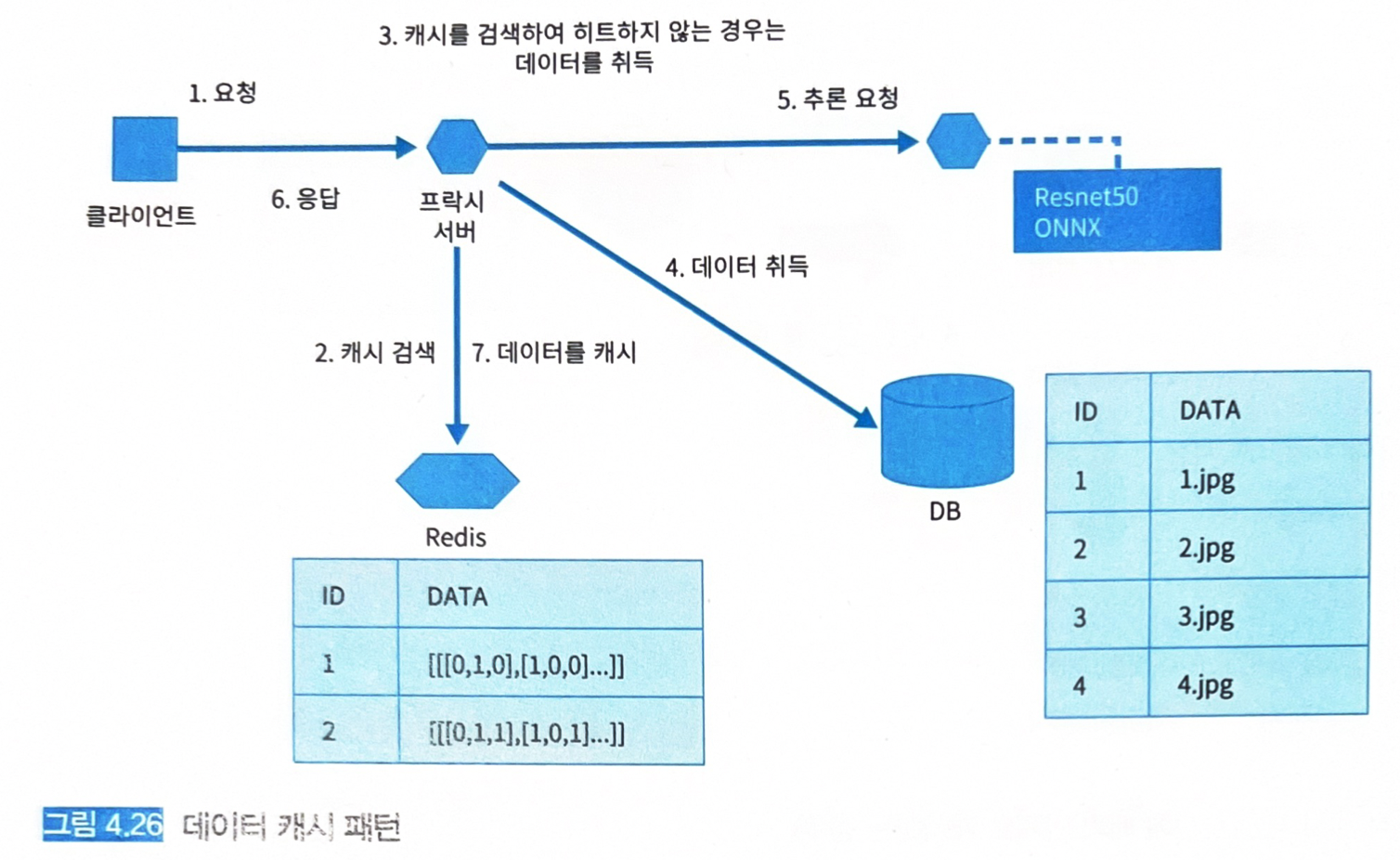
routers.py: https://github.com/shibuiwilliam/ml-system-in-actions/blob/main/chapter4_serving_patterns/data_cache_pattern/src/app/routers/routers.py- 데이터 ID를 가지고
/predict/label로 요청할 경우,Classfier의predict_label메서드를 호출하는데, 이는 내부적으로predict메서드를 호출하게 된다.
... @router.post("/predict/label") def predict_label(data: Data, background_tasks: BackgroundTasks) -> Dict[str, str]: prediction = classifier.predict_label(data=data, background_tasks=background_tasks) return {"prediction": prediction} ...- 데이터 ID를 가지고
prediction.py: https://github.com/shibuiwilliam/ml-system-in-actions/blob/main/chapter4_serving_patterns/data_cache_pattern/src/ml/prediction.py- 전처리 후에 데이터를 캐시한다.
- 이미지 데이터의 사이즈를 변경하고 표준화한 뒤 캐시에 등록한다.
- 동일 데이터라면 캐시에서 검색해 추론기로 요청한다.
# ... # 추론 def predict( self, data: Data, background_tasks: BackgroundTasks, ) -> List[float]: # 캐시 검색 cache_data = background_job.get_data_redis(key=data.data) # 캐시가 히트하지 않는 경우 (registering cache: ... 로그를 남김) if cache_data is None: logger.info(f"registering cache: {data.data}") image = Image.open(os.path.join("data/", f"{data.data}.jpg")) preprocessed = self.preprocess_transformer.transform(image) # 백그라운드에서 캐시 등록 background_job.save_data_job( data=preprocessed.tolist(), item_id=data.data, background_tasks=background_tasks ) # 캐시가 히트한 경우 (cache hit: ... 로그를 남김) else: logger.info(f"cache hit: {data.data}") preprocessed = np.array(cache_data).astype(np.float32) input_tensor = onnx_ml_pb2.TensorProto() input_tensor.dims.extend(preprocessed.shape) input_tensor.data_type = 1 input_tensor.raw_data = preprocessed.tobytes() request_message = predict_pb2.PredictRequest() request_message.inputs[self.onnx_input_name].data_type = input_tensor.data_type request_message.inputs[self.onnx_input_name].dims.extend(preprocessed.shape) request_message.inputs[self.onnx_input_name].raw_data = input_tensor.raw_data response = self.stub.Predict(request_message) output = np.frombuffer(response.outputs[self.onnx_output_name].raw_data, dtype=np.float32) softmax = self.softmax_transformer.transform(output).tolist() logger.info(f"predict proba {softmax}") return softmax # ...-
도커 컴포즈로 기동했다고 가정하고, 다음과 같이 테스트 요청할 수 있다.
# 데이터 ID 0000을 요청 $ curl \ -X POST \ -H "Content-Type: application/json" \ -d '{"data": "0000"}' \ localhost:8000/predict/label {"prediction":"Persian cat"} # 데이터 ID 0000을 재차 요청 $ curl \ -X POST \ -H "Content-Type: application/json" \ -d '{"data": "0000"}' \ localhost:8000/predict/label {"prediction":"Persian cat"} # 로그에서 캐시를 확인 $ docker logs proxy | grep cache [2021-01-01 08:44:04] [INFO] [src.ml.prediction] registering cache: 0000 [2021-01-01 08:44:05] [INFO] [src.ml.prediction] cache hit: 0000 - 데이터 전처리가 복잡하고 연산량이 많을수록 데이터 캐시의 가치는 올라간다.
4.11.5 이점
- 데이터 취득이나 전처리, 특징 추출의 오버헤드를 줄일 수 있음.
- 고속으로 추론 개시가 가능함.
4.11.6 검토사항
- 필요한 캐시 용량이 거대해질 수 있으므로 주의. (데이터 캐시는 추론 결과의 캐시보다 보통 더 큰 용량을 가진다)
- 캐시 메모리 비용에 대한 적절한 정책과 상황이 마련된다면 좋을 것.
4.12 추론기 템플릿 패턴
4.12.1 유스케이스
- 동일한 입출력의 추론기를 대량으로 개발하고 릴리즈하는 경우.
- 추론기 중 모델 이외의 부분을 공통화하는 경우.
4.12.2 해결하려는 과제
- 다른 OS나 파이썬 버전, 라이브러리 버전에서는 다른 운용방침을 만들어야 한다.
- 추론기 작성 방법을 정해 놓고 공통화 → 개발 중복 방지 & 운용의 간편함.
- 공통화 가능 요소
- 인프라
- OS
- 네트워크
- 인증인가
- 보안
- 로그 수집
- 감시 통보
- 머신러닝과 관련성이 없는 미들웨어나 라이브러리
- 웹 애플리케이션 서버나 작업 관리 서버 →
- REST API 라이브러리 및 Protocol Buffers와 gRPC
- 로그의 형식 - 네트워크, 보안은 인프라 엔지니어가 담당. - 로그 수집과 감시 통보는 머신러닝 엔지니어 (데이터, 추론 결과 등) 와 인프라 엔지니어 (앱 로그, 인프라 로그, 프로파일, 자원 사용률 등) 모두 담당. - 머신러닝과 관련성이 없는 미들웨어와 라이브러리는 소프트웨어 엔지니어가 선택.
- 인프라
- 머신러닝 모델의 고유한 요소 (머신러닝 모델을 가동시키기 위한 프로그래밍 언어와 라이브러리)
- 프로그래밍 언어의 버전
- 머신러닝 라이브러리의 버전
- 입출력 인터페이스
- 데이터의 전처리 및 후처리의 구현
4.12.3 아키텍처
-
추론기 코드나 인프라 구성, 배포 방침 등을 공통화해서 재사용성을 높인 템플릿을 준비한다 (그림 4.27)
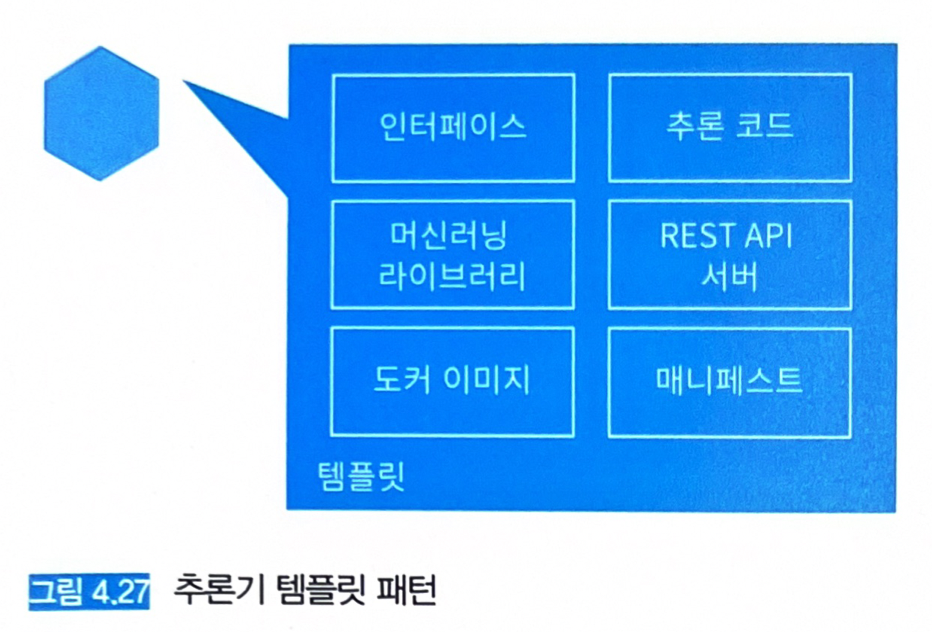
4.12.4 구현
jinja2라고 하는 파이썬의 템플릿 엔진을 사용해 추론기 템플릿을 작성한다. (.py,.html,.md,.yaml등 각종 확장자 파일을 읽고 지정한 변수를 변환할 수 있다)- 웹 싱글 패턴의 템플릿을 작성해본다:
- FastAPI로 웹 API 구현
- ONNX Runtime에 의한 추론 클래스
- Dockerfile
- 도커 컴포즈 매니페스트
- 쿠버네티스 매니페스트
routers.py.j2: https://github.com/shibuiwilliam/ml-system-in-actions/blob/main/chapter4_serving_patterns/template_pattern/template_files/routers.py.j2- jinja2에서는 ``를 사용하여 변환 대상이 될 변수를 지정한다.
# ... @router.get("/metadata") def metadata() -> Dict[str, Any]: return { "data_type": "", "data_structure": , "data_sample": , "prediction_type": "", "prediction_structure": , "prediction_sample": , } # ...vars.yaml: https://github.com/shibuiwilliam/ml-system-in-actions/blob/main/chapter4_serving_patterns/template_pattern/vars.yaml- 변환 대상 변수와 변환 후의 값은
vars.yaml에 기술한다.
name: sample model_file_name: iris_svc.onnx label_file_name: label.json data_type: float32 data_structure: (1,4) data_sample: [[5.1, 3.5, 1.4, 0.2]] prediction_type: float32 prediction_structure: (1,3) prediction_sample: [0.97093159, 0.01558308, 0.01348537]- 변환 대상 변수와 변환 후의 값은
correspond_file_path.yaml: https://github.com/shibuiwilliam/ml-system-in-actions/blob/main/chapter4_serving_patterns/template_pattern/correspond_file_path.yaml- 변환 후 파일을 배치할 파일 경로는
correspond_file_path.yaml에서 지정한다.
Dockerfile.j2: "{}/Dockerfile" prediction.py.j2: "{}/src/ml/prediction.py" routers.py.j2: "{}/src/app/routers/routers.py" deployment.yml.j2: "{}/manifests/deployment.yml" namespace.yml.j2: "{}/manifests/namespace.yml" makefile.j2: "{}/makefile" docker-compose.yml.j2: "{}/docker-compose.yml"- 변환 후 파일을 배치할 파일 경로는
builder.py: https://github.com/shibuiwilliam/ml-system-in-actions/blob/main/chapter4_serving_patterns/template_pattern/builder.py- 파일 변환 및 파일의 배치는
builder.py에서 실행한다. - CLI로 실행할 수 있는 인터페이스를 제공한다.
import os from distutils.dir_util import copy_tree from typing import Dict import click import yaml from jinja2 import Environment, FileSystemLoader TEMPLATE_DIRECTORY = "./template" TEMPLATE_FILES_DIRECTORY = "./template_files" # 변수 불러오기 def load_variable( variable_file: str, ) -> Dict: with open(variable_file, "r") as f: variables = yaml.load( f, Loader=yaml.SafeLoader, ) return variables # 경로를 수정 def format_path( correspond_file_paths: Dict, name: str, ) -> Dict: formatted_correspond_file_paths: Dict = {} for k, v in correspond_file_paths.items(): formatted_correspond_file_paths[k] = v.format(name) return formatted_correspond_file_paths # 양식을 담을 디렉터리 작성 def copy_directory(name: str): copy_tree(TEMPLATE_DIRECTORY, name) # 템플릿 파일로부터 추론기 파일을 작성 def build( template_file_name: str, output_file_path: str, variables: Dict, ): env = Environment( loader=FileSystemLoader("./", encoding="utf8"), ) tmpl = env.get_template( os.path.join( TEMPLATE_FILES_DIRECTORY, template_file_name, ), ) file = tmpl.render(**variables) with open(output_file_path, mode="w") as f: f.write(str(file)) @click.command(help="template pattern") @click.option( "--name", type=str, required=True, help="name of project", ) @click.option( "--variable_file", type=str, default="vars.yaml", required=True, help="path to variable file yaml", ) @click.option( "--correspond_file_path", type=str, default="correspond_file_path.yaml", required=True, help="file defining corresponding file path", ) def main( name: str, variable_file: str, correspond_file_path: str, ): variables = load_variable( variable_file=variable_file, ) correspond_file_paths = load_variable( variable_file=correspond_file_path, ) formatted_correspond_file_paths = format_path( correspond_file_paths=correspond_file_paths, name=name, ) os.makedirs(name, exist_ok=True) copy_directory(name=name) for k, v in formatted_correspond_file_paths.items(): build( template_file_name=k, output_file_path=v, variables=variables, ) if __name__ == "__main__": main()- 파일 변환 및 파일의 배치는
-
builder.py의 코드를 다음과 같이 실행하면 추론기의 양식을 생성할 수 있다. 여기서는sample이라고 하는 디렉터리에 추론기 양식을 작성한다.$ python \ -m builder \ --name sample \ --variable_file vars.yaml \ --correspond_file_path correspond_file_path.yaml
4.12.5 이점
- 개발 효율 향상
- 동일 운영 방침으로 관리 가능.
- 릴리즈나 통합 테스트의 공통화 가능.
4.12.6 검토사항
- 템플릿의 하위호환성과 업데이트 방침을 미리 정해둬야 한다.
- 모든 호환성을 유지하는 것은 불가능 → 일정한 과거 버전까지 (예를 들어 최신 두 개 버전까지) 지원하는 방침 마련.
4.13 에지 AI 패턴
4.13.1 유스케이스
- 디바이스에서 직접 추론하고 싶은 경우.
- 실시간으로 추론하고 싶은 경우.
- 보안 문제상 추론에 사용한 데이터를 서버 사이드로 송신하고 싶지 않은 경우.
- 디바이스의 컴퓨팅 리소스, 데이터, 전력량으로 전처리를 포함한 추론이 가능한 경우.
4.13.2 해결하려는 과제
- 에지 AI: 스마트폰 단말이나 자동차 내부에서 추론하여 실시간성을 확보하는 기술.
-
디바이스에서 직접 추론이 필요한 경우가 있다.
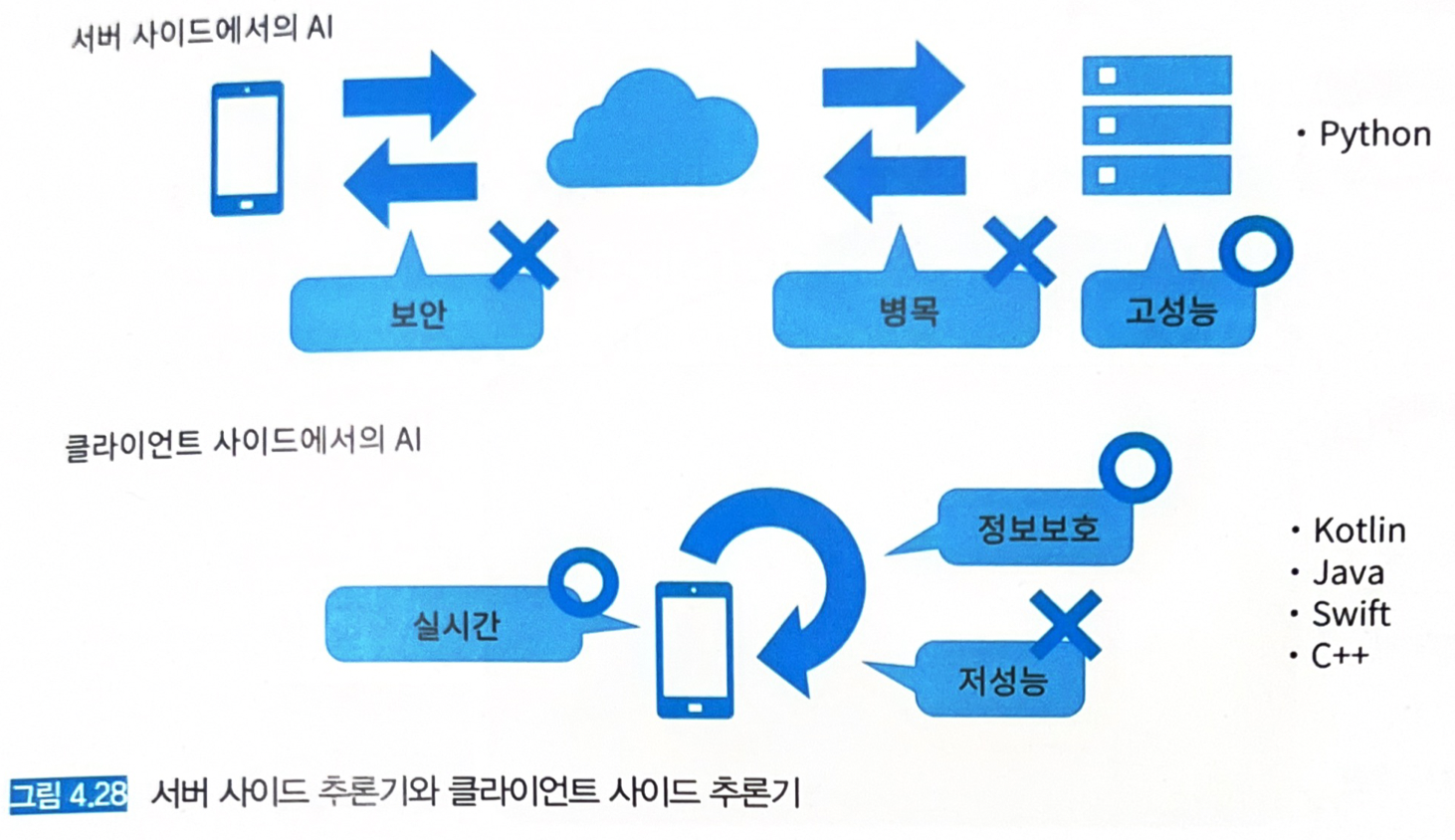
- 지연시간 최소화 (자율주행 자동차, 인터랙티브한 스마트폰 앱 등).
- 개인 정보를 서버사이드로 송신하지 않고 디바이스 안에서 추론하여 사용자 정보 보호.
- 스마트폰에서 딥러닝 모델의 추론을 실행하기 위한 모델 변환 기능이 여럿 있다.
- MobileNet 모델
- TensorFlow Lite
- PyTorch Mobile
-
하드웨어 측면에서도 에지 사이드에서 추론 자원을 제공하기 위한 것들이 있다.
- 구글 에지 TPU
- NVIDIA Jetson Nano
- CoreML
- NNAPI
4.13.3 아키텍처
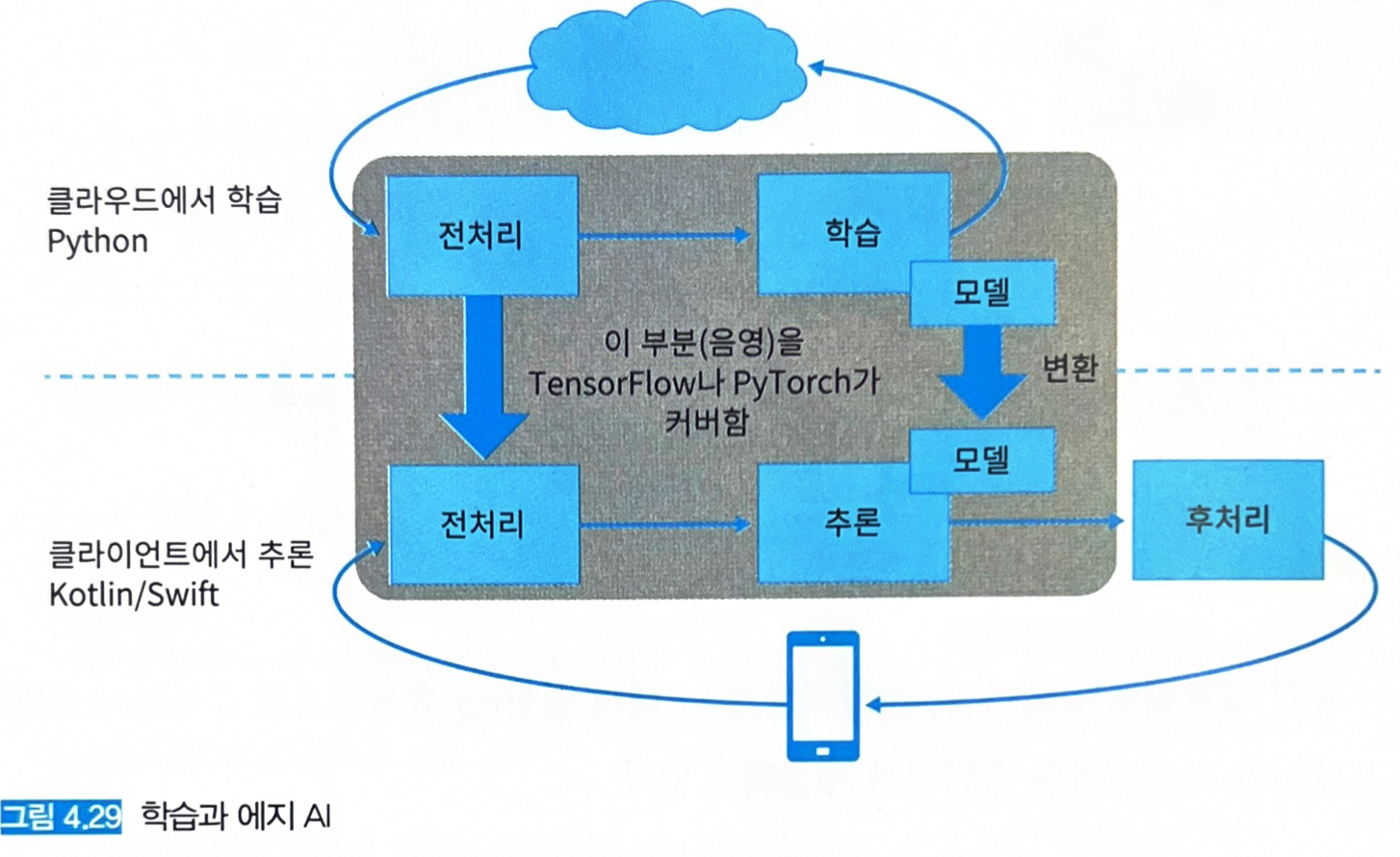
- 에지 사이드에서의 추론은 데이터 전처리, 추론, 후처리를 포함해 모두 디바이스 내부에서 실행한다.
- 딥러닝에 필요한 연산을 모두 에지사이드에서 실행해야 한다.
- 대기시간 발생을 최대한 회피해야 한다.
- 하드웨어, 컴파일, 소프트웨어 레벨에서 최적화 필요.
- 학습된 모델을 스마트폰 전용 모델로 변환해서 사용한다.
- 구글
mediapipe: 스마트폰으로 데이터의 입력부터 전처리, 추론, 후처리까지를 일련의 연산으로 변환해주는 라이브러리.
4.13.4 구현
- Android에서 TensorFlow Lite를 실행하는 샘플 프로그램 (카메라에 찍힌 이미지를 분류하고 화면에 그 추론 결과를 표시하는 프로그램)
TFLiteActivity.kt: https://github.com/shibuiwilliam/ml-system-in-actions/blob/main/chapter4_serving_patterns/edge_ai_pattern/app/src/main/java/com/shibuiwilliam/tflitepytorch/TFLiteActivity.kt- TensorFlow Lite에서 모델을 호출하고 Android 단말기 내에서 추론을 실행하는 코드. (
org.tensorflow.lite라이브러리로 호출할 수 있다)
// ... import org.tensorflow.lite.Interpreter import org.tensorflow.lite.gpu.GpuDelegate import org.tensorflow.lite.nnapi.NnApiDelegate // ... class TFLiteActivity : AbstractCameraXActivity() { private val TAG: String = TFLiteActivity::class.java.simpleName private lateinit var tfliteModel: MappedByteBuffer private lateinit var tfliteInterpreter: Interpreter // 모델 불러오기 private fun initializeTFLite(device: Constants.Device, numThreads: Int) { when (device) { Constants.Device.NNAPI -> { nnApiDelegate = NnApiDelegate() tfliteOptions.addDelegate(nnApiDelegate) } Constants.Device.GPU -> { gpuDelegate = GpuDelegate() tfliteOptions.addDelegate(gpuDelegate) } Constants.Device.CPU -> { } } tfliteOptions.setNumThreads(numThreads) tfliteModel = FileUtil.loadMappedFile(this, Constants.TFLITE_MOBILENET_V2_PATH) tfliteInterpreter = Interpreter(tfliteModel, tfliteOptions) } // 카메라에서 취득한 비트맵 이미지를 224 x 224로 리사이즈 및 표준화하고 tfliteInterpreter를 통해 추론 override fun analyzeImage(image: ImageProxy, rotationDegrees: Int): String? { try { var bitmap = Utils.imageToBitmap(image) bitmap = rotateBitmap(bitmap, 90f) val labeledProbability = classifyImage(bitmap) Log.i(TAG, "top${Constants.TOPK} prediction: ${labeledProbability}") return labeledProbability.map{it -> val p = "%,.2f".format(it.value) "${it.key}: ${p} \n" }.joinToString() } catch (e: Exception){ e.printStackTrace() return null } } // ...- TensorFlow Lite에서 모델을 호출하고 Android 단말기 내에서 추론을 실행하는 코드. (
4.13.5 이점
- 디바이스 내에서 추론이 가능해져 실시간에 가까운 속도로 추론 결과를 응답할 수 있음.
- 데이터를 외부로 노출시킬 필요가 없으므로 정보 보안과 관련된 위험을 경감할 수 있음.
- 데이터 스토리지 비용 감소, 통신 비용 감소.
4.13.6 검토사항
- 모델의 갱신, 수정이 어려움.
- 인터넷에 접속이 불가한 디바이스는 모델 갱신 때마다 디바이스를 회수해야 한다.
- 적절한 시기에 갱신하지 못하면 사용자 경험 저하.
- 애플리케이션의 용량이 커짐.
- 디바이스에 맞는 모델 개발 자체가 어려움.
- GPU, CPU 칩셋이 단말기마다 다르기 때문에 모든 단말에 최적화된 모델을 개발하는 것은 어려움.
- 유력 단말기 혹은 칩셋 몇 종으로 타겟을 줄이거나 범용적인 모델 (MobileNet)을 활용해야 한다.
4.14 안티 패턴 (온라인 빅사이즈 패턴)
4.14.1 상황
- 온라인 웹 서비스나 실시간 처리가 필요한 시스템에서 지연이 큰 추론 모델을 이용하고 있는 경우.
- 서비스가 요구하는 지연보다 머신러닝 모델이 실현 가능한 추론의 지연이 긴 않는 경우.
- 완료시간이 정해져 있는 배치 처리에서
추론 횟수 x 회당 추론 시간이 완료시간을 초과하는 경우.
4.14.2 구체적인 문제
- 한 번의 추론에 소요되는 시간이 시스템 요건을 충족할 수 있게 해야 하며, 비용 대비 효과를 전망할 수 있어야 하는 것이 우선이다.
- 복잡한 모델 → 모델 용량이 커짐 → 컨테이너 이미지 커짐 → 메모리 로딩 시간, 사용량 증가 → 자원의 비효율적 사용
- 만약 Accuracy가 99.999%로 추론이 가능하지만 CPU로 추론하여 1회 추론당 10초, 사이즈는 100MB가 넘는 모델이 있다고 하자 (그림 4.31 상단).
- 평가치는 비즈니스 요건을 충족하지만, 추론 소요 시간과 모델 사이즈를 단점으로 볼 수 있다. → 추론용 GPU를 사용해 추론시간을 단축할 수 있다.
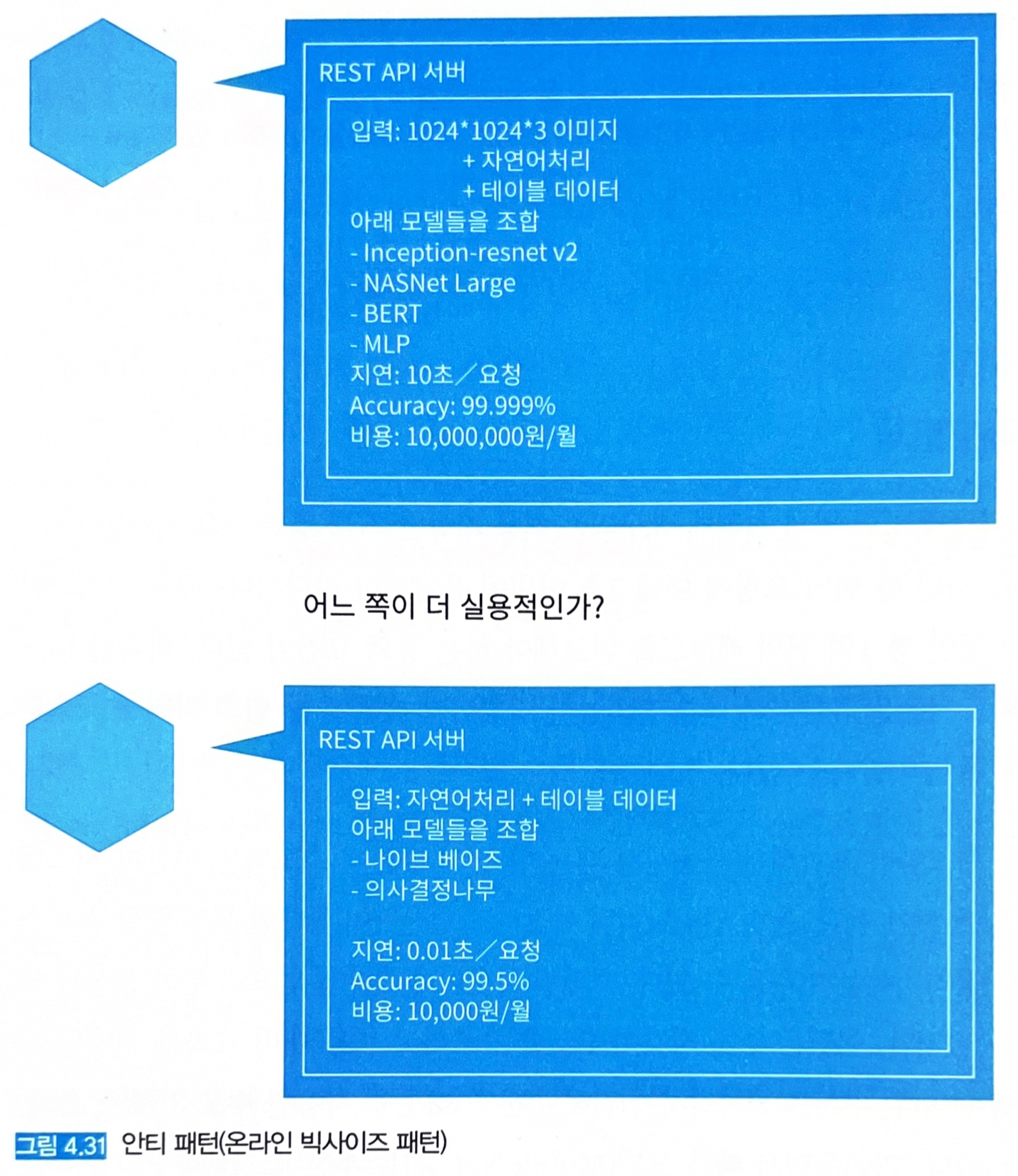
- 그림 4.31 하단에는 Accuracy가 99.5%지만 1회 추론당 평균 소요 시간이 0.01초이고 모델 사이즈는 10MB인 모델이 있다.
- 평가치는 상단 모델에 비해 약간 떨어지지만 합리적인 비용으로 빠르게 서비스를 제공한다는 점에서 더 실용적일 수 있다.
- 프로덕트 매니저, 소프트웨어 엔지니어, 머신러닝 엔지니어가 협력하여 서비스의 레벨을 정하는 것이 중요하다.
4.14.3 이점
- 연산량이 많고 복잡한 모델일수록 머신러닝의 평가치가 개선되는 경향이 있음.
- 일반적으로 복잡한 모델을 만드는 것이 즐거움.
4.14.4 과제
- 속도와 비용의 희생을 최소화해야 함.
- 간단하고 합리적인 모델을 만드는 것도 흥미로워해야 함.
4.14.5 회피 방법
- 추론기의 평가치 & 처리 시간을 정의하고 이 요건을 충족하는 모델을 개발함.
- 스케일 아웃 & 스케일 업, 추론용 GPU 사용 검토.
- 시간차 추론 패턴으로 경량화된 추론기와 무거운 추론기의 균형을 맞춤.
- 추론 캐시 패턴이나 데이터 캐시 패턴으로 고속화 도모.
4.15 안티 패턴 (올-인-원 패턴)
4.15.1 상황
- 여러 개의 추론 모델을 가동시키는 시스템에서 모든 모델이 동일한 서버에서 가동 중인 경우.
4.15.2 구체적인 문제
- 모든 추론 모델을 동일한 서버에서 가동시키는 것은 피해야 한다.
- 서버 비용은 저렴할 수 있으나, 모델 개발, 장애 분리, 갱신이 어려워 운영 비용이 오히려 늘어날 수 있다.
-
모놀리식 환경에서 장애가 발생하면 모든 로그로부터 검색해서 장애를 특정해야 한다 → 장애 대응 늦어짐.
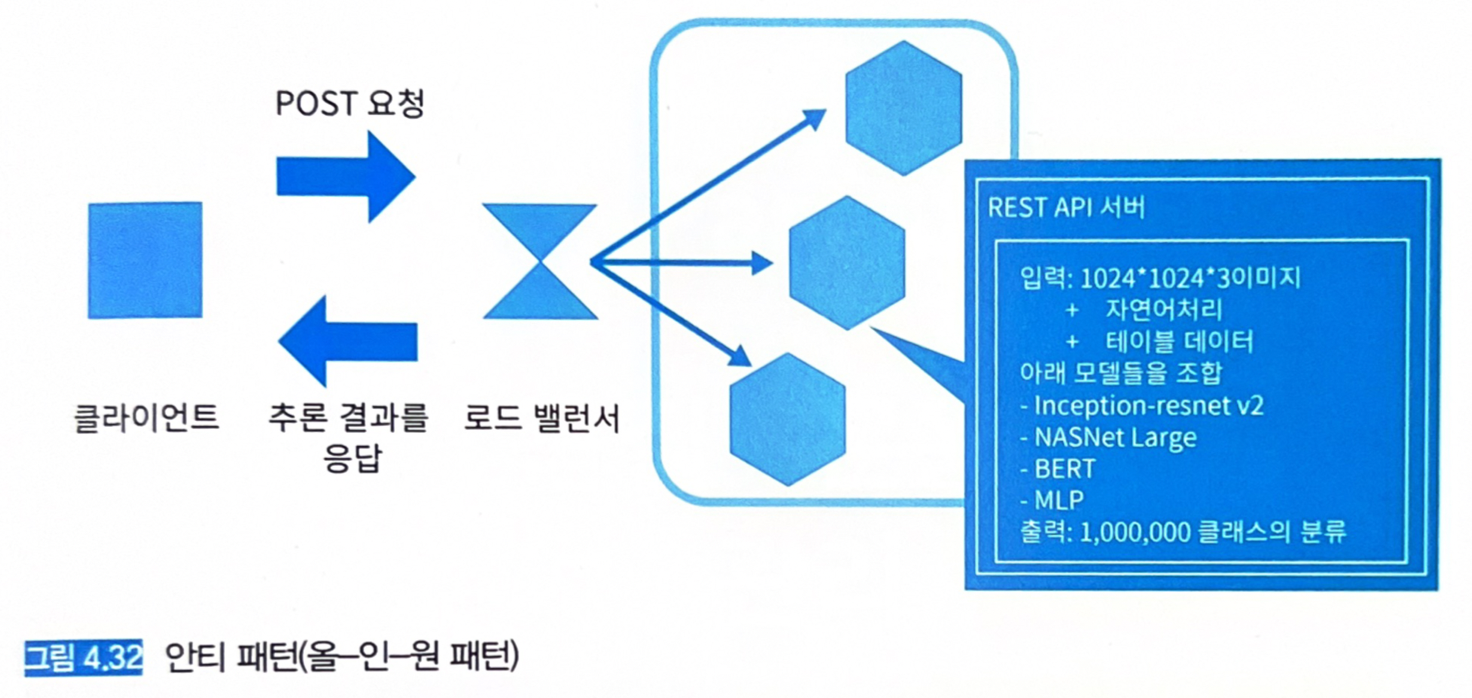
- 위와 같이 동일한 컨테이너 이미지에 여러 개의 모델이 포함 (모델-인-이미지 패턴) → 한 모델의 학습이 실패하면 모든 모델을 다시 학습해야 한다.
- 모든 모델의 정확도가 요건을 충족시킬 때까지 다시 학습을 시작하게 되는 경우가 생긴다.
- 모델과 추론기가 1:1로 대응하는 마이크로서비스로 운용하는 것을 권장한다.
4.15.3 이점
- 추론기 서버 비용을 아낄 수 있음.
4.15.4 과제
- 개발과 운용 비용이 증가.
4.15.5 회피 방법
- 각 추론 모델을 마이크로서비스로 구현하고 낮은 결합도로 운용.
- 병렬 마이크로서비스 패턴 활용.