[Study] 머신러닝 시스템 디자인 패턴 - Chapter 5
Chapter 5 - 머신러닝 시스템의 운용
5.1 머신러닝의 운용
- MLOps = ML (머신러닝) + Ops (운용) → 머신러닝 시스템을 운용하고 유지하는 것은 머신러닝을 효과적으로 활용함에 있어 중요하다.
- 비즈니스에 좋은 영향을 주는 경우 → 추론의 속도, 양, 정확도가 사람 예측보다 월등한 성능을 내는 경우 (비즈니스 가치에 대한 ”유효성 검증”)
- 머신러닝이 사람 예측보다 정확도가 높다고 해도, 속도가 느리고 적은 양의 추론밖에 해내지 못한다면 실제 시스템이 도입할 타당성이 떨어진다.
- 추론 대상의 데이터가 달라져 학습에 사용했던 데이터셋과 괴리가 커진다면?
- 사람의 예측이 머신러닝의 추론을 능가하게 된다.
- (e.g.) 2019년까지는 ‘코로나’라는 단어는 주로 ‘코로나 맥주’나 ‘태양을 둘러싼 코로나’라는 의미로 사용됐지만, 2020년부터는 ‘코로나 바이러스’의 의미로 사용하는 경우가 대부분이다.
- 이제는 ‘코로나 바이러스’의 의미를 포함하도록 데이터를 검토해야 한다.
- 머신러닝 시스템의 구성
- 학습 파이프라인: 데이터 수집, 전처리, 학습, 빌드, 평가
- 추론기의 릴리즈: 다른 소프트웨어와 통합해 정상 가동 검증
- 추론 시스템: 추론 요청에 대한 결과, 속도, 가용성을 고려한 정상 응답 검증
- 위 시스템들의 가동상황을 고려하여 이상 발생 여부를 감시하고 통보할 필요가 있다.
- 정상 여부 평가: 로그 수집 → 비정상적 경향이나 오류 감지 & 수정 (이번 장의 주제)
5.2 추론 로그 패턴
5.2.1 유스케이스
- 추론 결과나 소요 시간, 로그를 토대로 서비스를 개선하고 싶은 경우.
- 로그를 사용해 알람을 보내고 싶은 경우.
5.2.2 해결하려는 과제
- 수집과 분석 대상
- 추론 결과
- 추론 속도
- 클라이언트에 대한 영향
- 기타 이벤트 및 메트릭 (GPU 사용률, 통신 지연 등)
5.2.3 아키텍처
- 로그 분석을 위해서는 DWH나 로그 수집 기반으로 모으는 것이 좋다.
-
큐나 Fluentd와 같은 수집 도구를 채택하고, 이를 통해 로그를 수집한다 (그림 5.1).
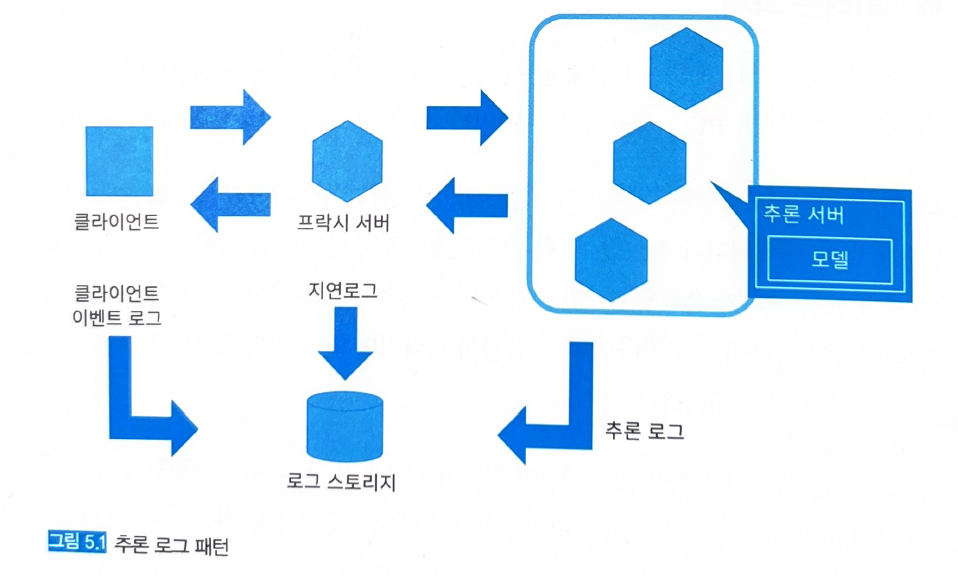
5.2.4 구현
- 추론기의 로그를 출력하고 감시 가능한 상태를 유지한다.
- 총 세 가지를 감시할 수 있어야 한다.
- 인프라로서의 추론기
- 추론기를 가동시키고 있는 인프라에 따라 결정.
- AWS라면 CloudWatch의 메트릭으로 감시할 수 있고, GCP는 CloudLogging 사용.
- 쿠버네티스 클러스터라면 노드와 컨테이너를 감시.
- 머신러닝 모델로 추론을 수행하는 추론기 애플리케이션
- 추론기를 웹 API로 가동시킨다면 웹의 외형감시와 내부감시.
- 배치 시스템이라면 각 배치 작업의 가동 여부 감시.
- 머신러닝의 추론 그 자체로서의 추론기
- 입력 데이터와 추론 결과 로그.
- 특정 라벨이나 수치에 편중되어 있는지 확인.
- 추론 코드가 잘못되었음: 앱 내부 및 모델에서 요청을 받고 추론하기까지의 입력 데이터의 변화를 로그로 출력해본다.
- 추론 모델이 실제 데이터를 반영하지 못함: 학습 데이터와 추론 데이터 사이의 괴리가 있는지 확인. 추론 데이터를 일정기간 수집한 후 분포나 경향의 차이를 확인해야 한다.
- 입력 데이터의 이상: 예상치 못한 데이터가 입력된 경우. 마찬가지로 장기적인 경향을 관찰.
- 인프라로서의 추론기
- 전체 코드: prediction_log_pattern
- 웹 API로 추론 시스템 구축 (FastAPI), 시스템은 쿠버네티스 클러스터에 구축.
- 입력 데이터의 이상 여부를 검지하기 위해 One-class SVM을 활용한 outlier 검지를 추론기에 추가한다.
-
엔드포인트: routers.py
import uuid from logging import getLogger from typing import Any, Dict, List from fastapi import APIRouter, HTTPException from src.ml.data import Data from src.ml.outlier_detection import outlier_detector from src.ml.prediction import classifier from src.utils.profiler import log_decorator logger = getLogger(__name__) router = APIRouter() @router.get("/health") def health() -> Dict[str, str]: return {"health": "ok"} @router.get("/metadata") def metadata() -> Dict[str, Any]: return { "data_type": "float32", "data_structure": "(1,4)", "data_sample": Data().data, "prediction_type": "float32", "prediction_structure": "(1,3)", "prediction_sample": [0.97093159, 0.01558308, 0.01348537], "outlier_type": "bool, float32", "outlier_structure": "(1,2)", "outlier_sample": [False, 0.4], } @router.get("/label") def label() -> Dict[int, str]: return classifier.label @log_decorator(endpoint="/predict/test", logger=logger) def _predict_test(job_id: str) -> Dict[str, Any]: logger.info(f"execute: [{job_id}]") prediction = classifier.predict(data=Data().data) is_outlier, outlier_score = outlier_detector.predict(data=Data().data) prediction_list = list(prediction) return { "job_id": job_id, "prediction": prediction_list, "is_outlier": is_outlier, "outlier_score": outlier_score, } @router.get("/predict/test") def predict_test() -> Dict[str, Any]: job_id = str(uuid.uuid4())[:6] return _predict_test(job_id=job_id) @log_decorator(endpoint="/predict/test/label", logger=logger) def _predict_test_label(job_id: str) -> Dict[str, Any]: logger.info(f"execute: [{job_id}]") prediction = classifier.predict_label(data=Data().data) is_outlier, outlier_score = outlier_detector.predict(data=Data().data) return { "job_id": job_id, "prediction": prediction, "is_outlier": is_outlier, "outlier_score": outlier_score, } @router.get("/predict/test/label") def predict_test_label() -> Dict[str, Any]: job_id = str(uuid.uuid4())[:6] return _predict_test_label(job_id=job_id) @log_decorator(endpoint="/predict", logger=logger) def _predict(data: Data, job_id: str) -> Dict[str, Any]: logger.info(f"execute: [{job_id}]") if len(data.data) != 1 or len(data.data[0]) != 4: raise HTTPException(status_code=404, detail="Invalid input data") prediction = classifier.predict(data.data) is_outlier, outlier_score = outlier_detector.predict(data=data.data) prediction_list = list(prediction) return { "job_id": job_id, "prediction": prediction_list, "is_outlier": is_outlier, "outlier_score": outlier_score, } @router.post("/predict") def predict(data: Data) -> Dict[str, Any]: job_id = str(uuid.uuid4())[:6] return _predict(data=data, job_id=job_id) @log_decorator(endpoint="/predict/label", logger=logger) def _predict_label(data: Data, job_id: str) -> Dict[str, str]: logger.info(f"execute: [{job_id}]") if len(data.data) != 1 or len(data.data[0]) != 4: raise HTTPException(status_code=404, detail="Invalid input data") prediction = classifier.predict_label(data.data) is_outlier, outlier_score = outlier_detector.predict(data=data.data) return { "job_id": job_id, "prediction": prediction, "is_outlier": is_outlier, "outlier_score": outlier_score, } @router.post("/predict/label") def predict_label(data: Data) -> Dict[str, Any]: job_id = str(uuid.uuid4())[:6] return _predict_label(data=data, job_id=job_id) - 로그 수집이나 이상치 검지를 위해 다음과 같은 조치를 취한다.
_predict와_predict_label함수에서 입력 데이터의 배열 사이즈가 4인 것을 필터링하고 4 이외에는 상태코드 404로 응답.outlier_detector로 입력 데이터의 이상 여부를 감지.- 추론 후의 응답에 작업 ID와 이상치 판정을 추가.
@log_decorator데코레이터로 작업 ID, 입력 데이터, 추론 결과, 이상치 검지 결과를 출력.
-
이상치 검지 구현: outlier_detection.py
from logging import getLogger from typing import List, Tuple import numpy as np import onnxruntime as rt from pydantic import BaseModel from src.configurations import ModelConfigurations from src.ml.data import Data logger = getLogger(__name__) class OutlierDetector(object): def __init__( self, outlier_model_filepath: str, outlier_lower_threshold: float, ): self.outlier_model_filepath: str = outlier_model_filepath self.outlier_detector = None self.outlier_input_name: str = "" self.outlier_output_name: str = "" self.outlier_lower_threshold = outlier_lower_threshold self.load_outlier_model() def load_outlier_model(self): logger.info(f"load outlier model in {self.outlier_model_filepath}") self.outlier_detector = rt.InferenceSession(self.outlier_model_filepath) self.outlier_input_name = self.outlier_detector.get_inputs()[0].name self.outlier_output_name = self.outlier_detector.get_outputs()[0].name logger.info(f"initialized outlier model") def predict(self, data: List[List[int]]) -> Tuple[bool, float]: np_data = np.array(data).astype(np.float32) prediction = self.outlier_detector.run(None, {self.outlier_input_name: np_data}) output = float(prediction[1][0][0]) is_outlier = output < self.outlier_lower_threshold logger.info(f"outlier score {output}") return is_outlier, output outlier_detector = OutlierDetector( outlier_model_filepath=ModelConfigurations().outlier_model_filepath, outlier_lower_threshold=ModelConfigurations().outlier_lower_threshold, ) -
@log_decorator데코레이터는 다음과 같이 구현한다. 함수 실행 전후의 시간 값을 받아 그 차이를 계산하고, 실행 시간, outlier 여부에 대한 로그를 남긴다: profiler.pyimport cProfile import time from logging import getLogger logger = getLogger(__name__) def do_cprofile(func): def profiled_func(*args, **kwargs): profile = cProfile.Profile() try: profile.enable() result = func(*args, **kwargs) profile.disable() return result finally: profile.print_stats() return profiled_func def log_decorator(endpoint: str = "/", logger=logger): def _log_decorator(func): def wrapper(*args, **kwargs): start = time.time() res = func(*args, **kwargs) elapsed = 1000 * (time.time() - start) # 걸린 시간을 계산한다. job_id = kwargs.get("job_id") data = kwargs.get("data") prediction = res.get("prediction") # 추론 결과인 res 객체로부터 logging할 변수를 얻는다. is_outlier = res.get("is_outlier") outlier_score = res.get("outlier_score") logger.info( # INFO level logging f"[{endpoint}] [{job_id}] [{elapsed} ms] [{data}] [{prediction}] [{is_outlier}] [{outlier_score}]" ) return res return wrapper return _log_decorator -
출력된 로그를 로그 수집 기반으로 송신하기 위해 Fluentd 사이드카 (Pods에 보조적으로 부여하는 컨테이너)를 추가한다. 로그의 송신은 GCP로 되어 있는데, Fluentd 설정을 실제 시스템에 맞춰 추론기의 로그를 로그 수집 기반으로 집약시킬 수 있다: manifest.yaml
apiVersion: apps/v1 kind: Deployment metadata: name: api namespace: prediction-log labels: app: api spec: replicas: 1 selector: matchLabels: app: api template: metadata: labels: app: api spec: containers: - name: api image: shibui/ml-system-in-actions:prediction_log_pattern_api_0.0.1 imagePullPolicy: Always env: - name: PORT value: "8000" ports: - containerPort: 8000 resources: limits: cpu: 500m memory: "300Mi" requests: cpu: 500m memory: "300Mi" volumeMounts: - name: varlog mountPath: /var/log - name: count-agent image: k8s.gcr.io/fluentd-gcp:1.30 # Sidecar로 fluentd를 띄운다. env: - name: FLUENTD_ARGS value: -c /etc/fluentd-config/fluentd.conf resources: limits: cpu: 128m memory: "300Mi" requests: cpu: 128m memory: "300Mi" volumeMounts: - name: varlog mountPath: /var/log - name: config-volume mountPath: /etc/fluentd-config volumes: - name: varlog emptyDir: {} - name: config-volume # ConfigMap을 사용하여 fluentd.conf를 구성한다. configMap: name: fluentd-config --- apiVersion: v1 kind: Service metadata: name: api namespace: prediction-log labels: app: api spec: ports: - name: rest port: 8000 protocol: TCP selector: app: api --- apiVersion: v1 kind: ConfigMap metadata: name: fluentd-config namespace: prediction-log data: # gunicorn log가 존재하는 path를 참조하도록 설정한다. fluentd.conf: | <source> type tail format none path /var/log/gunicorn_error.log pos_file /var/log/gunicorn_error.log tag gunicorn_error.log </source> <source> type tail format none path /var/log/gunicorn_access.log pos_file /var/log/gunicorn_access.log tag gunicorn_access.log </source> <match **> type google_cloud </match>
5.3 추론 감시 패턴
5.3.1 유스케이스
- 추론 결과를 감시해서 그 경향이 비정상적인 경우에 검지 및 통보하고 싶은 경우.
- 추론의 결괏값 또는 집계가 상정된 범위 안에 있음을 담보하고 싶은 경우.
- 추론의 속도나 입력 데이터의 이상 여부를 감시하고, 이상 시에 검지 및 통보하고 싶은 경우.
5.3.2 해결하려는 과제
- 추론기의 이상: 릴리즈 당시에 잘 작동하던 추론기가 갑자기 비정상적으로 바뀌는 일. 인프라나 부하에 원인이 있을 가능성이 높다.
- 추론 결과가 예상을 벗어남: 입력의 형태를 체크하거나 변환을 추가.
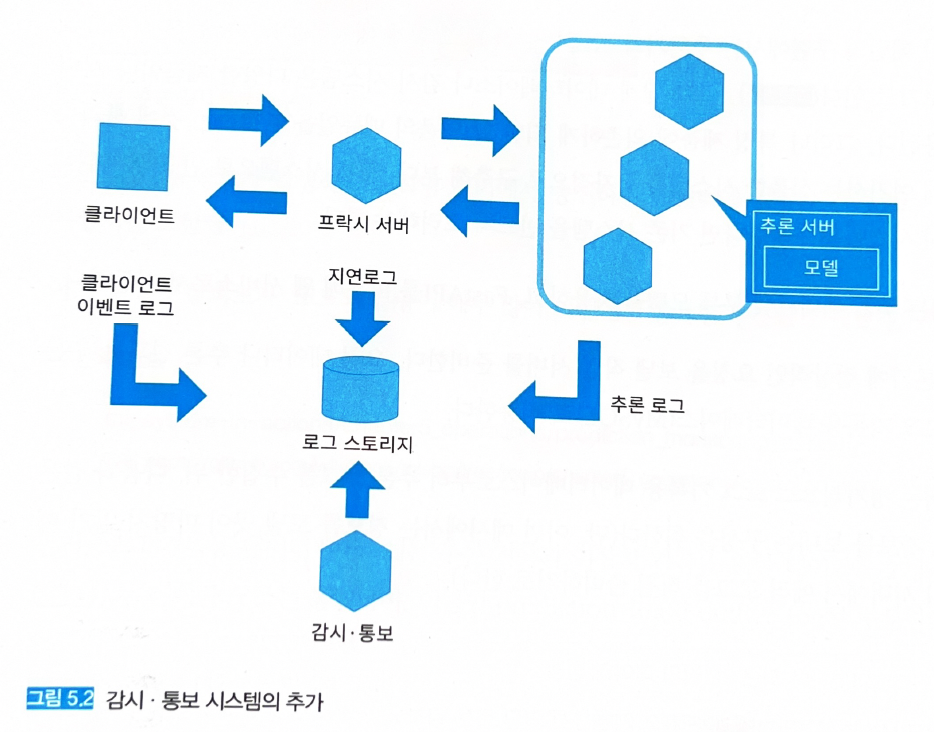
5.3.3 아키텍처
-
비정상적인 상태를 앞서 정의하고 감시 통보하는 시스템이 필요하다 (그림 5.2).
-
정기적으로 로그를 압축해 비용을 절감하는 것이 좋다.
5.3.4 구현
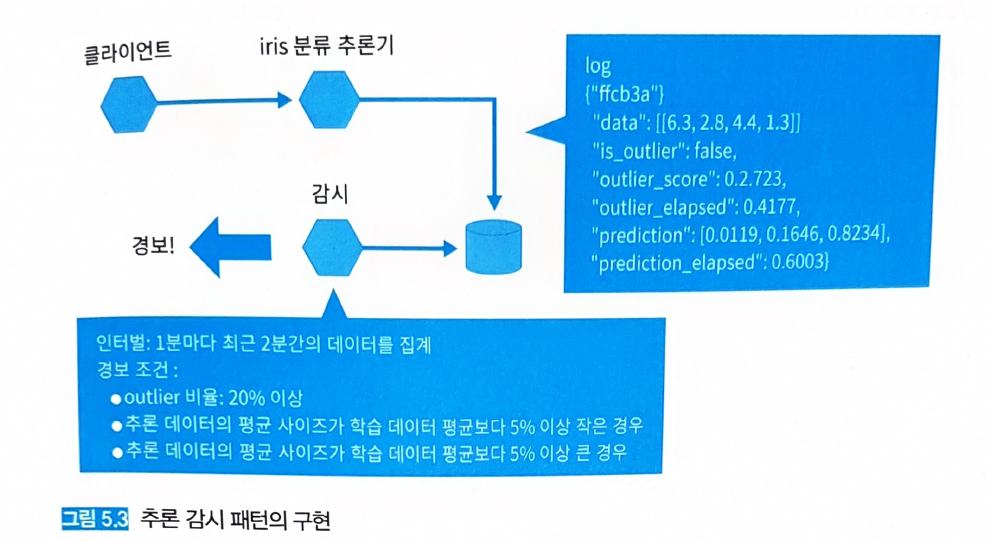
- 1분마다 최근 2분간의 데이터를 집계.
- 이상치 비율이 전체 20%를 초과할 경우 알람.
- 입력 데이터 감시: 추론 데이터의 평균 사이즈가 학습 데이터 평균 크기와 5% 이상 차이날 경우 알람.
- 감시 코드: src/monitor/main.py
import datetime import time from logging import DEBUG, Formatter, StreamHandler, getLogger from typing import List import click from src.db import cruds, schemas from src.db.database import get_context_db logger = getLogger(__name__) logger.setLevel(DEBUG) formatter = Formatter("[%(asctime)s] [%(process)d] [%(name)s] [%(levelname)s] %(message)s") handler = StreamHandler() handler.setLevel(DEBUG) handler.setFormatter(formatter) logger.addHandler(handler) def evaluate_prediction( average_sepal_length: float, average_sepal_width: float, average_petal_length: float, average_petal_width: float, threshold: float, prediction_logs: List[schemas.PredictionLog], ): logger.info("evaluate predictions...") sepal_lengths = [0.0 for _ in prediction_logs] sepal_widths = [0.0 for _ in prediction_logs] petal_length = [0.0 for _ in prediction_logs] petal_width = [0.0 for _ in prediction_logs] for i, p in enumerate(prediction_logs): sepal_lengths[i] = p.log["data"][0][0] sepal_widths[i] = p.log["data"][0][1] petal_length[i] = p.log["data"][0][2] petal_width[i] = p.log["data"][0][3] pred_average_sepal_length = sum(sepal_lengths) / len(sepal_lengths) pred_average_sepal_width = sum(sepal_widths) / len(sepal_widths) pred_average_petal_length = sum(petal_length) / len(petal_length) pred_average_petal_width = sum(petal_width) / len(petal_width) # 특정 임계값을 넘을 경우, 경보 목적으로 ERROR level logging을 한다. if pred_average_sepal_length < average_sepal_length * ( 1 - threshold ) or pred_average_sepal_length > average_sepal_length * (1 + threshold): logger.error(f"average sepal length out of threshold: {pred_average_sepal_length}") if pred_average_sepal_width < average_sepal_width * ( 1 - threshold ) or pred_average_sepal_width > average_sepal_width * (1 + threshold): logger.error(f"average sepal width out of threshold: {pred_average_sepal_width}") if pred_average_petal_length < average_petal_length * ( 1 - threshold ) or pred_average_petal_length > average_petal_length * (1 + threshold): logger.error(f"average petal length out of threshold: {pred_average_petal_length}") if pred_average_petal_width < average_petal_width * ( 1 - threshold ) or pred_average_petal_width > average_petal_width * (1 + threshold): logger.error(f"average petal width out of threshold: {pred_average_petal_width}") logger.info(f"average sepal length: {pred_average_sepal_length}") logger.info(f"average sepal width: {pred_average_sepal_width}") logger.info(f"average petal length: {pred_average_petal_length}") logger.info(f"average petal width: {pred_average_petal_width}") logger.info("done evaluating predictions") def evaluate_outlier( outlier_threshold: float, outlier_logs: List[schemas.OutlierLog], ): logger.info("evaluate outliers...") outliers = 0 for o in outlier_logs: if o.log["is_outlier"]: outliers += 1 if outliers > len(outlier_logs) * outlier_threshold: logger.error(f"too many outliers: {outliers}") logger.info(f"outliers: {outliers}") logger.info("done evaluating outliers") @click.command(name="request job") @click.option("--interval", type=int, default=1) @click.option("--outlier_threshold", type=float, default=0.2) @click.option("--average_sepal_length", type=float, default=5.84) @click.option("--average_sepal_width", type=float, default=3.06) @click.option("--average_petal_length", type=float, default=3.76) @click.option("--average_petal_width", type=float, default=1.20) @click.option("--threshold", type=float, default=0.05) def main( interval: int, outlier_threshold: float, average_sepal_length: float, average_sepal_width: float, average_petal_length: float, average_petal_width: float, threshold: float, ): logger.info("start monitoring...") while True: now = datetime.datetime.now() interval_ago = now - datetime.timedelta(minutes=(interval + 1)) # 1분마다 과거 2분 데이터를 얻도록 한다. time_later = now.strftime("%Y-%m-%d %H:%M:%S") time_before = interval_ago.strftime("%Y-%m-%d %H:%M:%S") logger.info(f"time between {time_before} and {time_later}") with get_context_db() as db: # DB 접근 prediction_logs = cruds.select_prediction_log_between(db=db, time_before=time_before, time_later=time_later) outlier_logs = cruds.select_outlier_log_between(db=db, time_before=time_before, time_later=time_later) logger.info(f"prediction_logs between {time_before} and {time_later}: {len(prediction_logs)}") logger.info(f"outlier_logs between {time_before} and {time_later}: {len(outlier_logs)}") if len(prediction_logs) > 0: evaluate_prediction( average_sepal_length=average_sepal_length, average_sepal_width=average_sepal_width, average_petal_length=average_petal_length, average_petal_width=average_petal_width, threshold=threshold, prediction_logs=prediction_logs, ) if len(outlier_logs) > 0: # 이상치가 있을 경우 evaluate_outlier( outlier_threshold=outlier_threshold, outlier_logs=outlier_logs, ) time.sleep(interval * 60) if __name__ == "__main__": main()
5.4 안티 패턴 (로그가 없는 패턴)
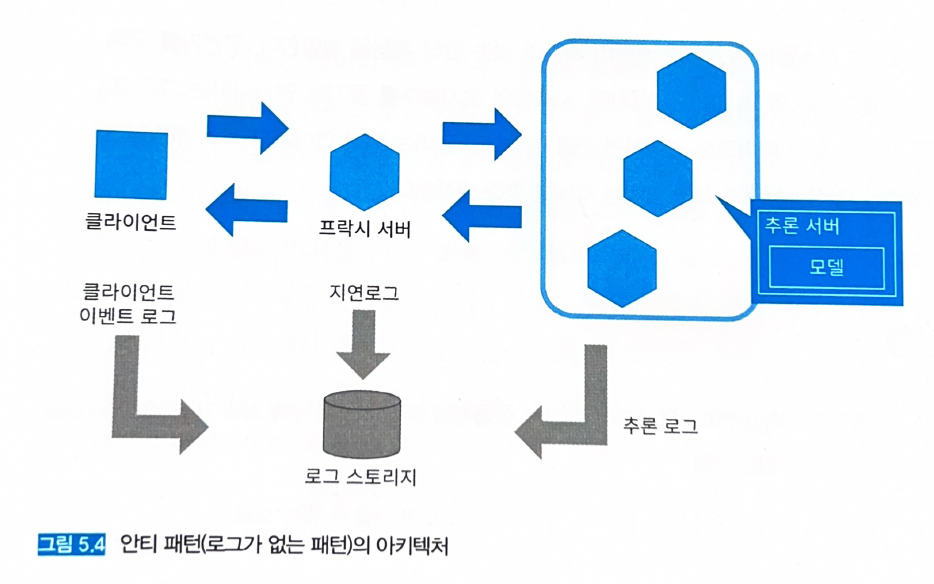
- 그림 5.4처럼 로그를 수집하지 않으면 에러 검지나 장애 대응, 시스템 개선을 수행할 수 없어서 블랙박스 시스템으로 전락한다.
- 굳이 장점을 따지자면 스토리지 비용 절감…(?)
- 빠른 시일 내 로그 시스템을 구축해야 한다.
5.5 안티 패턴 (‘그리고 아무도 없었다…’ 패턴)
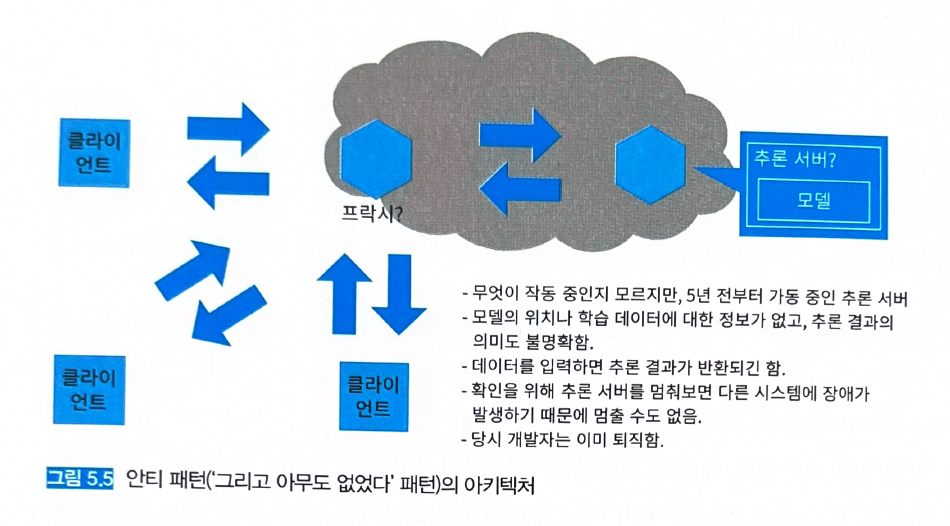
- 모델을 개발했던 엔지니어가 없거나 (퇴직했거나) 이해하고 있는 사람이 없는 상태.
- 당연한 소리지만, 이런 사태는 미리 방지해야 한다.