[Study] 머신러닝 시스템 디자인 패턴 - Chapter 6
Chapter 6 - 머신러닝 시스템의 품질관리
6.1 - 머신러닝의 품질과 운용
- 머신러닝 시스템이 비정상적인 경우
- 추론기의 이상
- 애플리케이션이나 인프라의 이상 정지나 지연
- 가동 중인 애플리케이션이 인프라나 미들웨어와 상성이 좋지 않아 정지 또는 성능이 열화된 상태.
- 소프트웨어 버그나 인프라의 고장, 디그레이드에 의한 정지 및 지연이 발생하는 상태.
- 추론 결과가 예상을 벗어남
- 로직의 이상
- 모델이나 코드의 알고리즘, 조건 분기가 잘못되어 있어 예상을 벗어난 처리나 출력을 수행하는 경우.
- 추론기의 이상
- 머신러닝 시스템의 평가 방법
- 런타임이나 OS의 정상 가동 평가
-
평균 고장 간격 (MTBF)과 평균 수복시간 (MTTR)을 사용해 다음의 가동률로 판별할 수 있다.
가동률 = MTBF / (MTBF + MTTR)
-
- 예상을 벗어난 추론 결과가 나타난 경우
- 분류 모델이라면 Precision이나 Recall 지표를 사용.
- 회귀라면 RMSE나 MAE 지표를 사용.
- 특정 연령대와 같은 그룹에 관한 평가를 실시해도 좋다.
- 런타임이나 OS의 정상 가동 평가
6.2 - 머신러닝 시스템의 정상성 평가 지표
6.2.1 머신러닝의 정상성
- 평가 관리
- 학습의 평가와 버전 관리
- 머신러닝 모델의 미비함 관리
- 데이터 관리
- 학습 및 평가 데이터 관리
6.2.2 소프트웨어의 정상성
- 변경 관리
- 모델이나 소프트웨어의 버전 관리 및 정합성 관리
- 인시던트 관리
- 소프트웨어 장애 관리
- 운용 관리
- 운용 시스템 관리
- 운용 체제 관리
- 테스트 관리
- 테스트 시스템 관리
- 머신러닝 시스템 릴리즈 판정 관리:
6.3 - 부하 테스트 패턴
6.3.1 유스케이스
- 추론 서버의 응답속도를 측정하고 싶은 경우.
- 추론 서버의 액세스 부하 테스트를 실시해서 실제 환경에 필요한 자원을 측정하고 싶은 경우.
6.3.2 해결하려는 과제
- 응답속도와 동시 액세스가 가능한 수는 서비스의 가용성과 직결되는 매우 중요한 수치다.
- 모델이 좋더라도 이러한 요구사항이 맞지 않는다면 비즈니스로 성립하지 않을 수 있다.
6.3.3 아키텍처
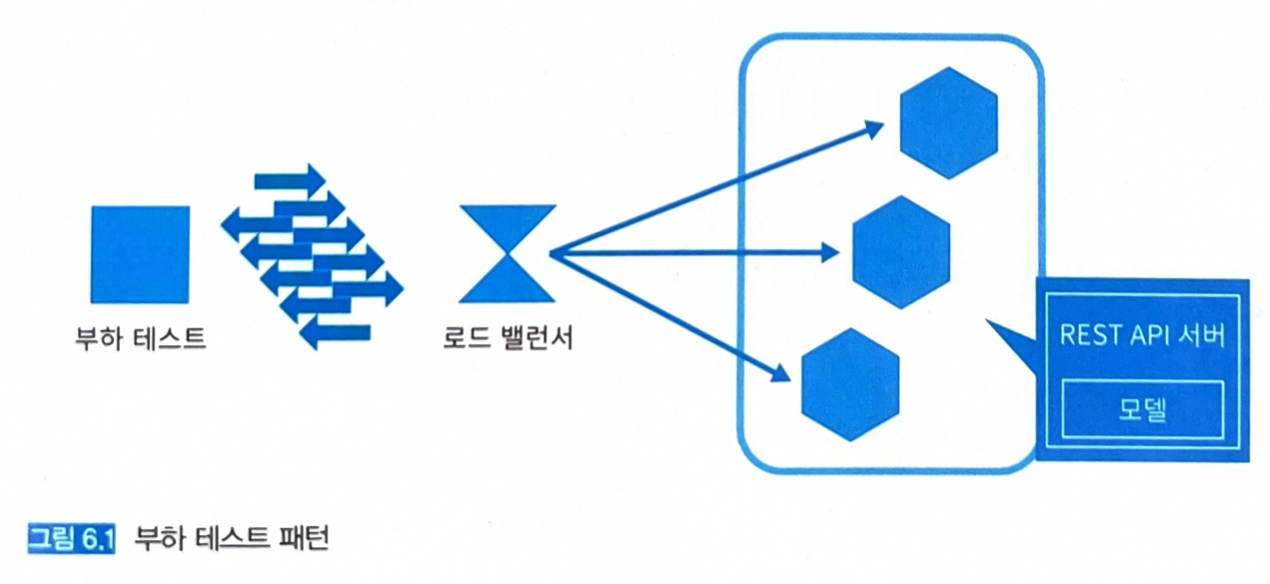
- 기존의 웹 서비스나 온라인 시스템에서 행해왔던 부하 테스트를 추론기에 대해 실시한다.
- 실제 서비스에서 입력하는 데이터의 사이즈가 무작위라면 부하 테스트에서도 그 크기를 무작위로 실행할 필요가 없다.
6.3.4 구현
- 쿠버네티스 클러스터 + 웹 싱글 패턴
- 부하 테스트 툴: vegeta attack
-
커맨드라인에서 쉽게 사용할 수 있는 툴로 웹 API에 대해 경량으로 고부하를 가할 수 있다.

-
-
부하 테스트 툴의 매니페스트: 원본 코드
apiVersion: v1 kind: Pod metadata: name: client namespace: load-test spec: containers: - name: client image: shibui/ml-system-in-actions:load_test_pattern_client_0.0.1 imagePullPolicy: Always command: - tail - -f - /dev/null resources: requests: cpu: 1000m # CPU 사용량 고정 memory: "1000Mi" # 메모리 사용량 고정 volumeMounts: - name: client mountPath: "/opt/vegeta" readOnly: true volumes: - name: client configMap: name: client --- apiVersion: v1 kind: ConfigMap metadata: name: client namespace: load-test data: # 웹 API의 GET 액세스 get-target: "GET http://iris-svc.load-test.svc.cluster.local:8000/predict/test" # 웹 API의 POST 액세스 post-target: "POST http://iris-svc.load-test.svc.cluster.local:8000/predict\nContent-Type: application/json\n@/opt/data.json" - CPU, 메모리 사용량을 고정하는 이유: 어느 정도의 부하에서 요청을 보낼 수 없게 되는지 가늠하기 위해 테스트 툴의 자원 사용량을 지정하는 것을 권장한다.
- 테스트 툴에 접속해 커맨드라인에서 추론기 API에 대해 부하 테스트를 수행한다.
- 초당 100의 POST 요청을 60초간 실행한다.
$ kubectl -n load-test exec -it pod/client bash $ vegeta attack -duration=60s -rate=100 -targets=vegeta/post-target | vegeta report -type=text # 출력 결과 # 요청 수 # Requests [total, rate, throughput] 6000, 100.02, 100.01 # 부하 검증 시간 # Duration [total, attack, wait] 59.992s, 59.99s, 1.915ms # 지연 # Latencies [min, mean, 50, 90, 95, 99, max] 1.246ms, 1.939ms, 1.928ms, 2.182ms, 2.279ms, 2.72ms, 23.222ms # Bytes In [total, mean] 438000, 73.00 # Bytes Out [total, mean] 210000, 35.00 # Success [ratio] 100.00% # Status Codes [code:count] 200:6000- 99%의 요청이 2.72ms 내에 응답하고 있음을 알 수 있다.
- 만약 추론 시스템에 대한 최대 요청 수가 50 정도라면 위의 결과로 안심하고 릴리즈할 수 있을 것이다.
-
조금 더 부하 테스트를 진행하여 초당 500의 요청을 전송해본다.
$ vegeta attack -duration=60s -rate=500 -targets=vegeta/post-target | vegeta report -type=text # 출력 결과 # 요청 수 # Requests [total, rate, throughput] 30000, 500.02, 499.98 # 부하 검증 시간 # Duration [total, attack, wait] 1m0s, 59.998s, 4.469ms # 지연 # Latencies [min, mean, 50, 90, 95, 99, max] 1.09ms, 2.29ms, 1.56ms, 2.39ms, 2.88ms, 26.03ms, 72.65ms # Bytes In [total, mean] 2190000, 73.00 # Bytes Out [total, mean] 1050000, 35.00 # Success [ratio] 100.00% # Status Codes [code:count] 200:30000- 전체 요청에 대해 정상적으로 응답할 수는 있었지만, 초당 100의 요청에 비해 지연이 발생하고 있다.
-
만약 초당 1,000의 요청이라면 어떨까
$ vegeta attack -duration=60s -rate=500 -targets=vegeta/post-target | vegeta report -type=text # 출력 결과 # 요청 수 # Requests [total, rate, throughput] 60000, 999.93, 390.80 # 부하 검증 시간 # Duration [total, attack, wait] 1m14s, 1m0s, 14.272s # 지연 # Latencies [min, mean, 50, 90, 95, 99, max] 1.25ms, 10.19s, 9.30s, 18.74s, 22.07s, 29.70s, 30.04s # Bytes In [total, mean] 2118971, 35.32 # Bytes Out [total, mean] 1015945, 16.93 # Success [ratio] 48.38% # Status Codes [code:count] 0:30973 200:29027- Success 결과가 48.38%로, 절반 이상의 요청이 실패했고, 지연도 평균 10초에 가까운 상태를 보였다.
- 이것으로 위의 추론 시스템은 현재 리소스로 초당 500의 요청은 견딜 수 있지만, 1,000이 넘는 요청은 에러가 발생하는 것으로 진단할 수 있다.
6.4 - 추론 서킷브레이커 패턴
6.4.1 유스케이스
- 추론기의 액세스가 급격히 증감하는 경우.
- 급격한 액세스 증감을 추론 서버나 인프라가 대응할 수 없는 경우.
- 전 요청에 응답을 반환할 필요가 없는 경우.
6.4.2 해결하려는 과제
- 일부 요청을 일부러 처리하지 않는 선택을 하는 것이 서킷브레이커의 핵심이다.
- 부하가 급증했을 때 일정 이상의 요청은 서버에 전송하지 않고 프락시에서 자동으로 에러를 응답한다.
- 에러를 반환하면서 요청 증가에 대응할 수 있도록 스케일 아웃 완료를 기다리는 것으로, 매우 합리적인 구조다.
6.4.3 아키텍처
-
일정 이상의 빈도로 발생하는 요청을 프락시로 차단해 추론 서버로 송신되는 요청 수를 처리 가능한 양으로 제한한다.
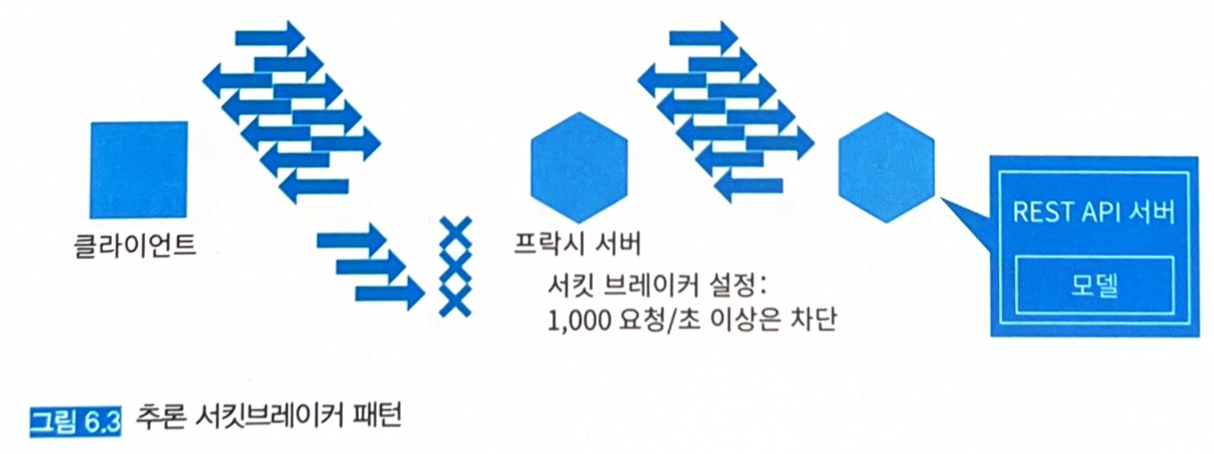
6.4.4 구현
- 쿠버네티스 클러스터로 서킷브레이커를 도입하고 vegeta attack으로 부하를 걸도록 한다.
-
Istio 애드온 툴: 마이크로서비스 아키텍처를 실현하고, 서비스 간 상호 통신을 지원하기 위한 기능을 제공한다.
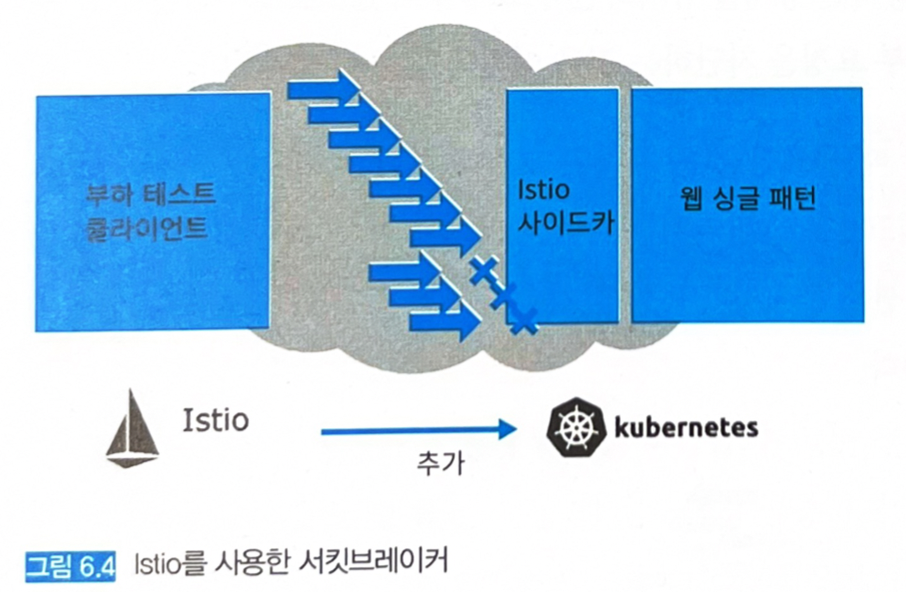
- 그 일부에 네트워크 제어를 위한 프락시가 존재한다 (Istio 사이드카)
- 트래픽 관리 (통신 라우팅 및 규칙 설정), 보안 (인증 인가, 암호화, 통신 거부 등), 로깅 (Service Trace 및 감시)를 제공한다.
- 일정 이상의 조회 수를 차단할 수 있다.
istioctl이라고 하는 커맨드라인 툴로 관리할 수 있다.-
쿠버네티스 클러스터에 Istio 도입은 다음과 같이 실행한다.
$ istioctl install - 이미 가동 중인 클러스터에서는 외부 접근이 중단될 수 있으니 스테이징 환경에서 사전 검증해야 한다.
- Istio를 설치한 쿠버네티스 클러스터에서 Istio를 사용하는 구성으로 자원을 배포하면 Pods에 envoy 프락시라고 하는 사이드카가 추가될 것이다.
- envoy 프락시가 추가된 Pods에서는 인바운드, 아웃바운드 통신이 모두 envoy 프락시를 경유하여 실행된다.
- envoy 프락시는 DestinationRule이라는 기능을 가지고 있다.
- DestinationRule에서는 부하 분산이나 타임아웃, failover 등의 통신 제어를 설정해 부하 대책을 실현한다.
- Istio DestinationRule을 추가한 Deployment manifest: 원본 코드
apiVersion: apps/v1
kind: Deployment
metadata:
name: iris-svc
namespace: circuit-breaker
labels:
app: iris-svc
spec:
replicas: 3
selector:
matchLabels:
app: iris-svc
template:
metadata:
labels:
app: iris-svc
version: svc
annotations: # Istio를 사용한 설정
sidecar.istio.io/inject: "true"
sidecar.istio.io/proxyCPU: "128m"
sidecar.istio.io/proxyMemory: "128Mi"
proxy.istio.io/config: "{'concurrency':'4'}"
spec:
containers:
- name: iris-svc
image: shibui/ml-system-in-actions:circuit_breaker_pattern_api_0.0.1
imagePullPolicy: Always
ports:
- containerPort: 8000
resources:
limits:
cpu: 500m
memory: "300Mi"
requests:
cpu: 500m
memory: "300Mi"
volumeMounts:
- name: workdir
mountPath: /workdir
env:
- name: MODEL_FILEPATH
value: "/workdir/iris_svc.onnx"
- name: WORKERS
value: "8"
initContainers:
- name: model-loader
image: shibui/ml-system-in-actions:circuit_breaker_pattern_loader_0.0.1
imagePullPolicy: Always
command:
- python
- "-m"
- "src.main"
- "--gcs_bucket"
- "ml_system_model_repository"
- "--gcs_model_blob"
- "iris_svc.onnx"
- "--model_filepath"
- "/workdir/iris_svc.onnx"
volumeMounts:
- name: workdir
mountPath: /workdir
volumes:
- name: workdir
emptyDir: {}
---
apiVersion: v1
kind: Service
metadata:
name: iris-svc
namespace: circuit-breaker
labels:
app: iris-svc
spec:
ports:
- name: rest
port: 8000
protocol: TCP
selector:
app: iris-svc
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: iris-svc
namespace: circuit-breaker
spec:
host: iris-svc
trafficPolicy:
loadBalancer:
simple: ROUND_ROBIN
connectionPool:
tcp:
maxConnections: 100 # 최대 접속 수
http:
http1MaxPendingRequests: 100 # 최대 요청 수
maxRequestsPerConnection: 100 # 커넥션의 최대 요청 수
# 고부하 대처
outlierDetection:
# 계속되는 장애임을 판정하는 값
consecutiveErrors: 100
# 에러 판정 간격 (초)
interval: 1s
# 에러일 경우 에러를 반환하는 최소 간격 (밀리초)
baseEjectionTime: 10m
maxEjectionPercent: 10
subsets:
- name: svc
labels:
version: svc
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: iris-svc
namespace: circuit-breaker
spec:
hosts:
- iris-svc
http:
- route:
- destination:
host: iris-svc
subset: svc
weight: 100
- 부하 테스트 툴의 manifest는 Istio로 인한 어노테이션이 추가된 것 외에는 부하 테스트 패턴과 동일하다: 원본 코드
apiVersion: v1
kind: Pod
metadata:
name: client
namespace: circuit-breaker
annotations:
sidecar.istio.io/inject: "true"
sidecar.istio.io/proxyCPU: "128m"
sidecar.istio.io/proxyMemory: "128Mi"
proxy.istio.io/config: "{'concurrency':'16'}"
spec:
containers:
- name: client
image: shibui/ml-system-in-actions:circuit_breaker_pattern_client_0.0.1
imagePullPolicy: Always
command:
- tail
- -f
- /dev/null
resources:
requests:
cpu: 1000m
memory: "1000Mi"
volumeMounts:
- name: client
mountPath: "/opt/vegeta"
readOnly: true
volumes:
- name: client
configMap:
name: client
---
apiVersion: v1
kind: ConfigMap
metadata:
name: client
namespace: circuit-breaker
data:
get-target: "GET http://iris-svc.circuit-breaker.svc.cluster.local:8000/predict/test"
post-target: "POST http://iris-svc.circuit-breaker.svc.cluster.local:8000/predict\nContent-Type: application/json\n@/opt/data.json"
- 위와 같은 구성으로 초당 1,000의 요청으로 부하 테스트를 실시해보자.
$ kubectl -n circuit-breaker exec -it pod/client -- bash
$ vegeta attack -duration=10s -rate=1000 -targets=vegeta/post-target | vegeta report -type=text
# 출력
# Requests [total, rate, throughput] 10000, 1000.04, 764.34
# Duration [total, attack, wait] 10.242s, 10s, 241.972ms
# Latencies [min, mean, 50, 90, 95, 99, max] 362.662µs, 177.282ms, 90.438ms, 427.767ms, 672.361ms, 1.419s, 2.929s
# Bytes In [total, mean] 747376, 74.74
# Bytes Out [total, mean] 350000, 35.00
# Success [ratio] 78.28%
# Status Codes [code:count] 200:7828 503:2172
# Error Set:
# 503 Service Unavailable
- 부하 테스트 패턴에서는 평균 지연이 10초였는데, 현재는 99%에 대해 1.4초로 많이 개선된 것을 확인할 수 있다.
- 에러율은 22% 정도고, 차단한 통신은 상태 코드 503 (Service temporarily unavailable)을 응답하는 것으로 모두 서킷브레이커를 통한 것임을 알 수 있다.
6.4.6 검토사항
- Istio의 서킷브레이커 기능은 Nginx도 제공한다.
- Istio 도입이 어려운 환경이라면 Nginx를 이용한 서킷브레이커가 더 범용적으로 사용될 것이다.
- 차단된 요청에 대해 503으로 응답하고 있으나, 다른 내용으로 응답하는 것을 검토해도 좋다.
- 일정 이상의 요청은 비동기 추론 패턴을 이용해 큐에 쌓아 비동기적으로 응답하는 방법도 생각할 수 있다.
- 서킷브레이커의 임계치에도 검토가 필요하다.
- 임계치가 너무 낮으면 사용자 입장에서는 빈번한 에러로 인해 사용할 수 없는 시스템으로 전락한다.
- 추론 시스템이 견딜 수 없을 정도의 부하에서 대략 80% 정도의 서킷브레이커 임계치를 설정해 두면 여유를 가지고 효율적인 리소스 활용이 가능할 것이다.
6.5 - 섀도 A/B 테스트 패턴
6.5.1 유스케이스
- 새로운 추론 모델이 실제 데이터로 문제없이 추론 가능한지 확인하고 싶은 경우.
- 새로운 추론기가 실제 액세스의 부하로부터 견딜 수 있는지 확인하고 싶은 경우.
6.5.2 해결하려는 과제
- 온라인 A/B 테스트를 실행하는 경우, 실제 시스템에서 사용 중인 데이터로 유효한 추론을 수행하는지는 실제 릴리즈 전까진 알 수 없다.
- 사용자의 이탈 가능성이 있다.
- 온라인에서 A/B 테스트를 실시하기 이전 단계에서 새로운 모델과 추론기가 실제 데이터로 정상적으로 동작해 머신러닝 시스템으로서 실제 도입을 견뎌낼 수 있는지 검증한다면 더욱 안전하다.
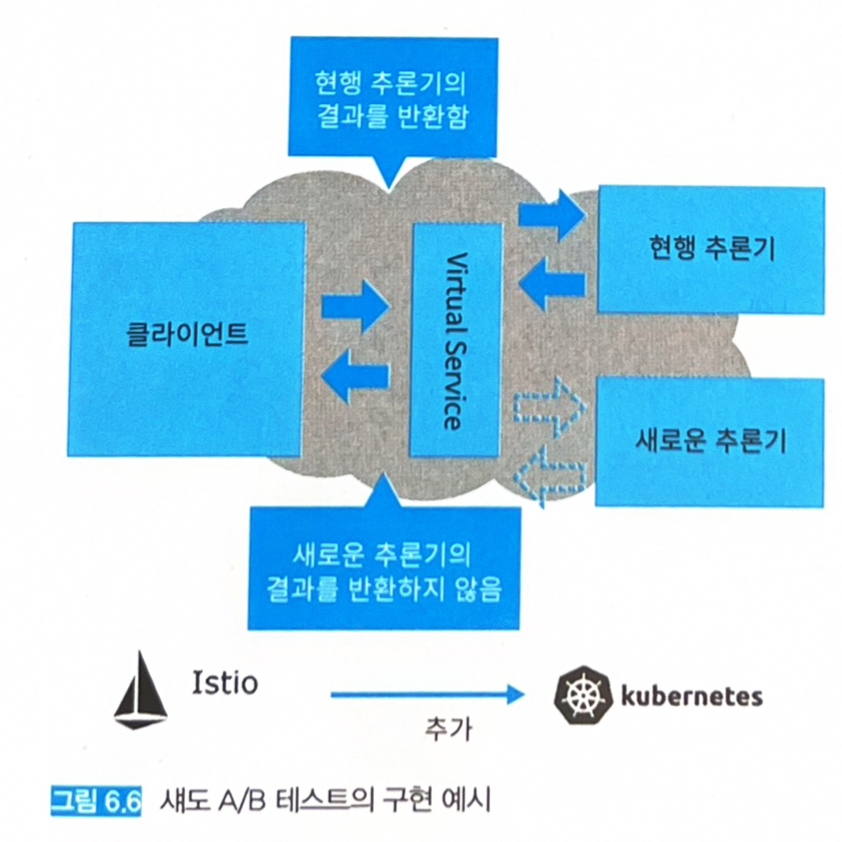
- 섀도 A/B 테스트 패턴에서는 실제 시스템에서 가동 중인 요청을 새롭게 가동시키려는 추론기에 미러링해서 추론 결과를 클라이언트에 반환하지 않으면서 추론만을 실행하는 시스템을 실현한다.
6.5.3 아키텍처
-
여러 개의 추론 모델과 추론기를 실제 데이터를 사용해 테스트하는 방법이다.
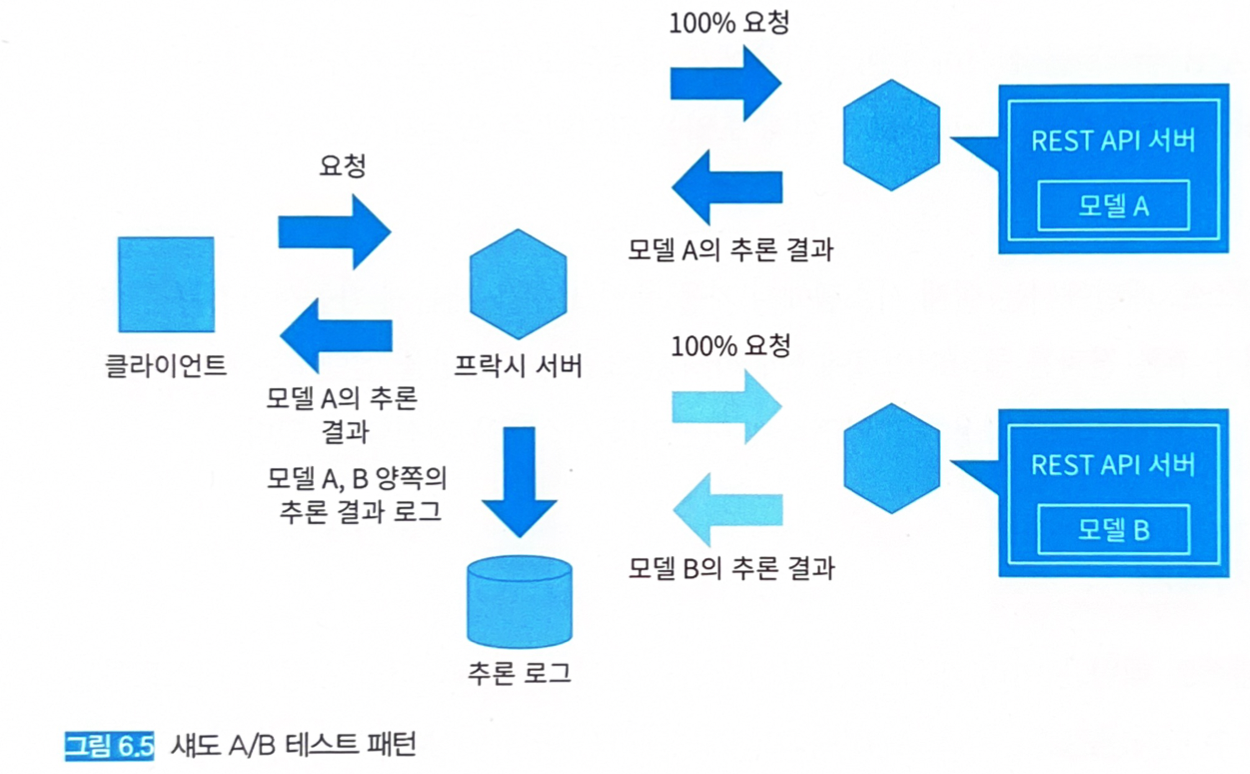
- 하나 이상의 추론기를 가동시킨다.
- 클라이언트와 추론기 사이에 프락시 서버를 배치한다.
- 프락시 서버는 추론 모델 모두에 요청을 보내지만, 클라이언트로 추론 결과를 반환하는 것은 현행 모델 뿐이다.
- 새로운 모델의 추론 결과는 클라이언트로 송신하지 않는다.
- 프락시 서버는 양쪽의 추론 결과를 분석용 DWH에 격리한다.
- 클라이언트에 영향을 끼치지 않고 새로운 모델의 추론 결과와 스피드를 측정해 실전 도입 여부를 판단하게 된다.
- 추론 결과나 속도, 가용성에 문제가 있는 경우는 새로운 추론 모델을 정지한다.
- 계측 기간: 계절성을 갖는 서비스라면 장기적으로 측정해야 하고, 매일 사용하는 서비스라면 1주일 정도로 결론을 낼 수 있을 것이다. 추론 결과와 그 영향을 보고 유연하게 판단한다.
- 섀도 A/B 테스트 패턴은 온라인 A/B 테스트 패턴과 달리 실제 비즈니스에 대한 리스크 없이 새로운 추론 모델을 시험할 수 있다.
- 섀도 A/B 테스트에서 추론 모델이 문제 없이 가동되는 것을 확인했다면 온라인 A/B 테스트 패턴으로 비즈니스 가치를 측정할 것을 권장한다.
6.5.4 구현
- Istio에는 서킷브레이커 외에도 여러 개의 트래픽을 엔드포인트에 미러링하는 기능이 있다.
- 트래픽 미러링을 이용해 현재의 추론기와 새로운 추론기에 모두 같은 요청을 보낼 수 있다.
- 두 가지 모델을 추론기로 가동시켜 보자.
- 붓꽃 데이터셋으로 학습한 다중 클래스 분류기
- 현행 추론기: 서포트 벡터 머신 모델
- 섀도 A/B 테스트 대상 추론기: 랜덤 포레스트 모델
- FastAPI, 구현은 웹 싱글 패턴과 같다.
- Istio VirtualService를 이용한다.
-
엔드포인트로의 통신 할당을 컨트롤하는 기능을 제공한다.
-
서포트 벡터 머신 추론기의 엔드포인트에 요청을 보내면서 랜덤 포레스트의 엔드포인트에도 동등한 요청을 보내 응답을 취득하지 않는 구성을 하는 것도 가능하다 (그림 6.6).
-
- VirtualService 설정을 포함한 deployment manifest: 원본 코드
apiVersion: apps/v1
kind: Deployment
metadata:
name: iris-svc # 현행 추론기
namespace: shadow-ab
labels:
app: iris-svc
spec:
replicas: 1
selector:
matchLabels:
app: iris
template:
metadata:
labels:
app: iris
version: svc
annotations: # Istio 설정
sidecar.istio.io/inject: "true"
sidecar.istio.io/proxyCPU: "128m"
sidecar.istio.io/proxyMemory: "128Mi"
proxy.istio.io/config: "{'concurrency':'4'}"
spec:
containers:
- name: iris-svc
image: shibui/ml-system-in-actions:shadow_ab_pattern_api_0.0.1
imagePullPolicy: Always
ports:
- containerPort: 8000
resources:
limits:
cpu: 500m
memory: "300Mi"
requests:
cpu: 500m
memory: "300Mi"
volumeMounts:
- name: workdir
mountPath: /workdir
env:
- name: MODEL_FILEPATH
value: "/workdir/iris_svc.onnx"
- name: WORKERS
value: "8"
initContainers:
- name: model-loader
image: shibui/ml-system-in-actions:shadow_ab_pattern_loader_0.0.1
imagePullPolicy: Always
command:
- python
- "-m"
- "src.main"
- "--gcs_bucket"
- "ml_system_model_repository"
- "--gcs_model_blob"
- "iris_svc.onnx"
- "--model_filepath"
- "/workdir/iris_svc.onnx"
volumeMounts:
- name: workdir
mountPath: /workdir
volumes:
- name: workdir
emptyDir: {}
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: iris-rf # 랜덤 포레스트를 사용한 새로운 추론기
namespace: shadow-ab
labels:
app: iris-rf
spec:
replicas: 1
selector:
matchLabels:
app: iris
template:
metadata:
labels:
app: iris
version: rf
annotations: # Istio 설정
sidecar.istio.io/inject: "true"
sidecar.istio.io/proxyCPU: "128m"
sidecar.istio.io/proxyMemory: "128Mi"
proxy.istio.io/config: "{'concurrency':'4'}"
spec:
containers:
- name: iris-rf
image: shibui/ml-system-in-actions:shadow_ab_pattern_api_0.0.1
imagePullPolicy: Always
ports:
- containerPort: 8000
resources:
limits:
cpu: 500m
memory: "300Mi"
requests:
cpu: 500m
memory: "300Mi"
volumeMounts:
- name: workdir
mountPath: /workdir
env:
- name: MODEL_FILEPATH
value: "/workdir/iris_rf.onnx"
- name: WORKERS
value: "8"
initContainers:
- name: model-loader
image: shibui/ml-system-in-actions:shadow_ab_pattern_loader_0.0.1
imagePullPolicy: Always
command:
- python
- "-m"
- "src.main"
- "--gcs_bucket"
- "ml_system_model_repository"
- "--gcs_model_blob"
- "iris_rf.onnx"
- "--model_filepath"
- "/workdir/iris_rf.onnx"
volumeMounts:
- name: workdir
mountPath: /workdir
volumes:
- name: workdir
emptyDir: {}
---
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: iris-svc
namespace: shadow-ab
labels:
app: iris-svc
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: iris-svc
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
---
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: iris-rf
namespace: shadow-ab
labels:
app: iris-rf
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: iris-rf
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
---
apiVersion: v1
kind: Service
metadata:
name: iris
namespace: shadow-ab
labels:
app: iris
spec:
ports:
- name: rest
port: 8000
protocol: TCP
selector:
app: iris
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: iris
namespace: shadow-ab
spec:
host: iris
trafficPolicy:
loadBalancer:
simple: ROUND_ROBIN
subsets:
- name: svc
labels:
version: svc
- name: rf
labels:
version: rf
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: iris
namespace: shadow-ab
spec:
hosts:
- iris
http:
- route:
- destination:
host: iris
subset: svc
weight: 100 # 100%의 요청을 서포트 벡터 머신 추론기에 송신
mirror: # 미러링
host: iris
subset: rf
mirrorPercentage:
value: 100.0 # 100%의 요청을 랜덤 포레스트 추론기에 미러링
- 모두 같은 포트번호 8000을 공유한 설정으로 되어 있지만, 클라이언트의 요청에 대한 응답은 서포트 벡터 머신 추론기에서만 되돌아오지 않으며, 랜덤 포레스트 추론기의 응답은 차단된다.
- 시험 삼아 포트번호 8000 엔드포인트에 요청을 보내 보자.
- 랜덤 포레스트 추론기로도 동시에 추론이 되고 있음을 로그를 통해 알 수 있다.
$ kubectl -n shadow-ab exec -it pod/client bash # 연속적으로 요청을 송신. # 모든 요청에 대해 응답이 같은 결과를 나타냄. $ curl http://iris.shadow-ab.svc.cluster.local:8000/predict-test/000000 # {"job_id":"000000","prediction":[0.9709315896034241,0.015583082102239132,0.013485366478562355]} $ curl http://iris.shadow-ab.svc.cluster.local:8000/predict-test/000000 # {"job_id":"000000","prediction":[0.9709315896034241,0.015583082102239132,0.013485366478562355]} $ curl http://iris.shadow-ab.svc.cluster.local:8000/predict-test/000000 # {"job_id":"000000","prediction":[0.9709315896034241,0.015583082102239132,0.013485366478562355]} $ curl http://iris.shadow-ab.svc.cluster.local:8000/predict-test/000000 # {"job_id":"000000","prediction":[0.9709315896034241,0.015583082102239132,0.013485366478562355]} $ curl http://iris.shadow-ab.svc.cluster.local:8000/predict-test/000000 # {"job_id":"000000","prediction":[0.9709315896034241,0.015583082102239132,0.013485366478562355]} # 랜덤 포레스트 Pod의 로그 $ kubectl -n shadow-ab logs pod/iris-rf-7cd8cb9d78-lcsq6 iris-rf # [2021-02-06 09:51:35] [INFO] [14] [src.app.routers.routers] [_predict_test] [37] execute: [000000] # [2021-02-06 09:51:35] [INFO] [14] [src.ml.prediction] [predict] [50] predict proba [0.99999994 0. 0. ] # [2021-02-06 09:51:35] [INFO] [14] [src.app.routers.routers] [wrapper] [33] [iris_rf.onnx] [/predict-test] [000000] [1.0628700256347656 ms] [None] [[0.9999999403953552, 0.0, 0.0]] # [2021-02-06 09:51:35] [INFO] [14] [uvicorn.access] [send] [458] 10.0.2.36:0 - "GET /predict-test/000000 HTTP/1.1" 200 # 서포트 벡터 머신 Pod의 로그 $ kubectl -n shadow-ab logs pod/iris-svc-74dc7654b8-xthmh iris-svc # [2021-02-06 09:51:35] [INFO] [8] [src.app.routers.routers] [_predict_test] [37] execute: [000000] # [2021-02-06 09:51:35] [INFO] [8] [src.ml.prediction] [predict] [50] predict proba [0.97093159 0.01558308 0.01348537] # [2021-02-06 09:51:35] [INFO] [8] [src.app.routers.routers] [wrapper] [33] [iris_svc.onnx] [/predict-test] [000000] [0.8084774017333984 ms] [None] [[0.9709315896034241, 0.015583082102239132, 0.013485366478562355]] # [2021-02-06 09:51:35] [INFO] [8] [uvicorn.access] [send] [458] 127.0.0.1:48148 - "GET /predict-test/000000 HTTP/1.1" 200
6.5.5 이점
- 실제 시스템에 영향을 주지 않으면서 새로운 모델과 동등한 상황에서 테스트할 수 있다는 점.
6.5.6 검토사항
- 새로운 추론기가 현행 추론기보다 우수한지는 머신러닝과 시스템, 두 가지 측면의 평가지표와 대조에 판단해야 한다.
6.6 - 온라인 A/B 테스트 패턴
6.6.1 유스케이스
- 새로운 추론 모델이 실제 데이터로 문제없이 추론 가능한지 확인하고 싶은 경우.
- 새로운 추론기가 실제 액세스의 부하에 견딜 수 있는지 확인하고 싶은 경우.
- 온라인으로 복수의 추론 모델의 비즈니스 가치를 측정할 경우.
- 새로운 추론 모델이 현행 추론 모델보다 나쁜 결과를 내지 않음을 확인하고 싶은 경우.
6.6.2 해결하려는 과제
- 섀도 A/B 테스트에서 새로운 추론기가 실제 시스템에서 정상 가동되는지 확인했으니, 온라인 A/B 테스트에서는 추론기를 실제 시스템의 일부에 릴리즈하고 모델의 유효성을 주변 시스템이나 사용자 영향으로부터 평가한다.
6.6.3 아키텍처
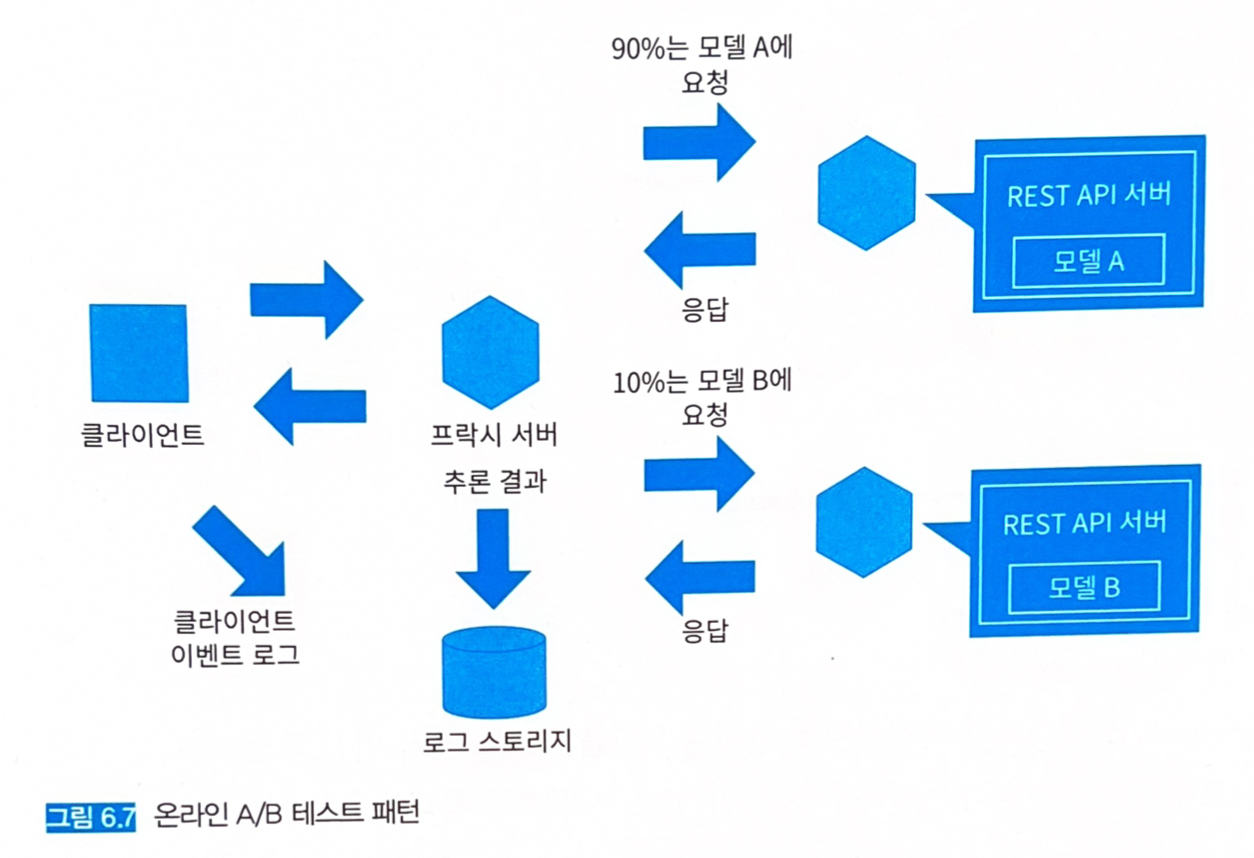
- 현행 추론기에 과반수의 액세스를 배분하면서 새로운 추론기에 서서히 액세스를 흘려보낸다.
- 액세스 양의 조정은 프락시 서버가 수행한다.
- 프락시 서버는 요청을 특정하는 ID와 입력 데이터, 그리고 추론 결과를 분석용 DWH에 격리한다.
- 추론을 얻은 클라이언트의 행동 로그를 수집해 새로운 모델과 기존 모델의 비교에 이용한다.
- 최종 사용자의 행동을 분석하고 싶다면 동일 사용자는 동일 추론기로 흘려보내는 것이 좋다.
- 위반 검지와 같이 추론 결과를 모아두는 것이라면, 무작위로 배분하거나 양쪽 모두에 액세스시키는 전략을 생각할 수 있다.
6.6.4 구현
-
Istio VirtualService를 활용한다.
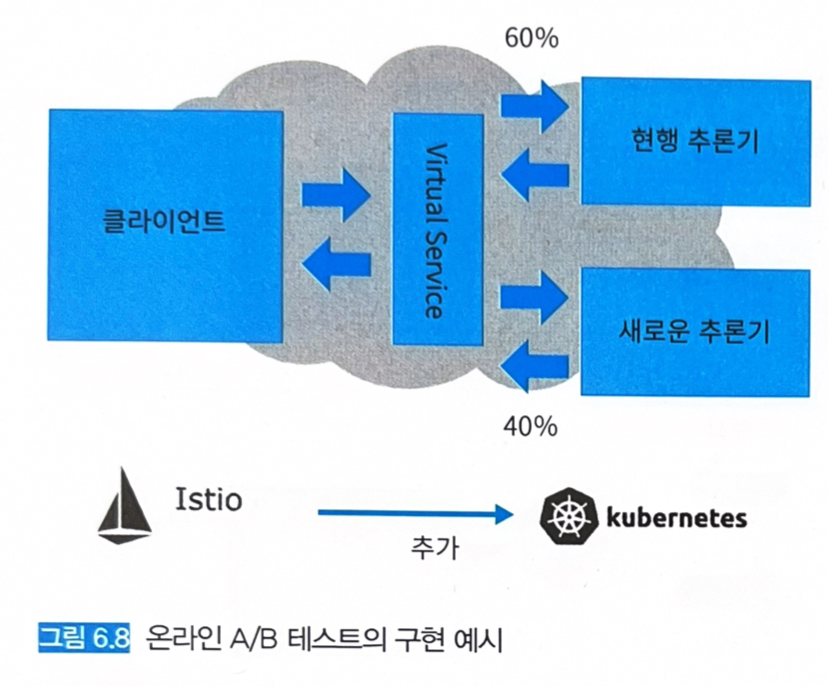
- VirtualService는 트래픽 미러링뿐만 아니라 트래픽 분할도 가능하다.
- 복수의 엔드포인트에 요청을 송신하는 비율을 지정해서 요청의 일부를 현행 추론기로, 나머지는 새로운 추론기로 나누어 송신할 수 있게 된다.
- 섀도 A/B 테스트와 마찬가지로 현행 추론기를 서포트 벡터 머신 모델, 새로운 추론기를 랜덤 포레스트 모델로 구현한다. 섀도 A/B 테스트와의 차이는 추론기의 VirtualService 설정 뿐이다.
- 추론기의 manifest: 원본 코드
# 나머지 Deployment 설정은 섀도 A/B 테스트 패턴과 동일하므로 생략.
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: iris
namespace: online-ab
spec:
hosts:
- iris
http:
- route:
- destination:
host: iris
subset: svc
weight: 60 # 기존 모델에 60% 요청
- destination:
host: iris
subset: rf
weight: 40 # 랜덤 포레스트 모델에 40% 요청
- 서포트 벡터 머신에 부하를 60%로 설정하고 랜덤 포레스트 모델에는 40%의 부하를 지정했다.
- 실제로 트래픽이 분할되고 있는지 확인해 보자.
$ kubectl -n online-ab exec -it pod/client bash
# 테스트로 10번 요청을 송신
$ curl http://iris.online-ab.svc.cluster.local:8000/predict/test
# {"prediction":[0.9709315896034241,0.015583082102239132,0.013485366478562355],"mode":"iris_svc.onnx"}
$ curl http://iris.online-ab.svc.cluster.local:8000/predict/test
# {"prediction":[0.9709315896034241,0.015583082102239132,0.013485366478562355],"mode":"iris_svc.onnx"}
$ curl http://iris.online-ab.svc.cluster.local:8000/predict/test
# {"prediction":[0.9999999403953552,0.0,0.0],"mode":"iris_rf.onnx"}
$ curl http://iris.online-ab.svc.cluster.local:8000/predict/test
# {"prediction":[0.9709315896034241,0.015583082102239132,0.013485366478562355],"mode":"iris_svc.onnx"}
$ curl http://iris.online-ab.svc.cluster.local:8000/predict/test
# {"prediction":[0.9709315896034241,0.015583082102239132,0.013485366478562355],"mode":"iris_svc.onnx"}
$ curl http://iris.online-ab.svc.cluster.local:8000/predict/test
# {"prediction":[0.9999999403953552,0.0,0.0],"mode":"iris_rf.onnx"}
$ curl http://iris.online-ab.svc.cluster.local:8000/predict/test
# {"prediction":[0.9999999403953552,0.0,0.0],"mode":"iris_rf.onnx"}
$ curl http://iris.online-ab.svc.cluster.local:8000/predict/test
# {"prediction":[0.9709315896034241,0.015583082102239132,0.013485366478562355],"mode":"iris_svc.onnx"}
$ curl http://iris.online-ab.svc.cluster.local:8000/predict/test
# {"prediction":[0.9709315896034241,0.015583082102239132,0.013485366478562355],"mode":"iris_svc.onnx"}
$ curl http://iris.online-ab.svc.cluster.local:8000/predict/test
# {"prediction":[0.9999999403953552,0.0,0.0],"mode":"iris_rf.onnx"}
- 응답 내부의 mode라는 키로 어느 추론기에서 응답하고 있는지 명시하고 있다.
- 서포트 벡터 머신이 6회, 랜덤 포레스트가 4회로, weight가 잘 적용된 것을 확인할 수 있다 (실제로는 횟수가 다를 수 있으나 이해를 위해 정확히 6회, 4회가 나온다고 보면 된다).
6.6.5 이점
- 실제 시스템에 도입해 사용자에 대한 영향을 확인할 수 있다.
6.6.6 검토사항
- 새로운 모델과 현행 모델의 트래픽 분할 비율
- Istio VirtualService처럼 추론기를 정지하지 않고도 트래픽 양을 컨트롤할 수 있다면 새로운 모델로의 유입량은 1% 정도부터 점차 늘려가는 것을 권장한다.
6.7 - 파라미터 기반 추론 패턴
6.7.1 유스케이스
- 추론기나 추론 결과를 변수로 제어하고 싶은 경우.
- 추론기를 룰 베이스로 제어하는 경우.
6.7.2 해결하려는 과제
- 머신러닝의 추론은 확률적인 것으로, 그 결과가 항상 옳다고 할 수 없다.
- 예를 들어 False positive (위양성)을 피하기 위해 붓꽃 데이터셋 [setosa, versicolor, virginca]의 분류 모델의 추론 결과가 [0.98, 0.01, 0.01]을 얻어내어 이를 setosa로 응답하는 것은 안전한 선택이지만, [0.34, 0.33, 0.33]과 같은 결과가 나왔을 때 이를 setosa로 응답하는 것은 False positive가 발생할 리스크가 크다.
- 이렇게 분류 관련 태스크는 확률의 크고 작음이 비즈니스에 영향을 끼칠 수 있다.
- 위반 감지나 추천 시스템에서는 확률이 낮은 분류 결과를 채택하지 않고, 일부러 모두 부정적으로 응답하여 어느 클래스로도 분류하지 않겠다는 전략도 구사할 수 있다.
- 각 클래스에 임곗값을 설정해 두고, 그 임곗값을 밑도는 추론 결과는 응답 대상으로 하지 않는 방식이다.
- 이 전략이 유효한지는 별도의 검증이 필요하며, 앞서 언급한 온라인 A/B 테스트가 유효할 것이다.
- 클래스별 임곗값의 튜닝을 통해 추론의 가치를 향상시킬 수 있다.
6.7.3 아키텍처
-
비정상적인 추론에 대비해 추론을 정지하거나 일부 데이터를 추론에서 제외, 재시도나 타임아웃 등 시스템 안에서 추론기를 운용하는 데 필요한 로직을 심어두면 바로 대응할 수 있다.

- 컨테이너형 시스템인 경우 환경 변수로 지정 가능한 변수를 준비해 두는 것이 좋다.
- 아무리 정확도가 높은 모델이라도 모든 엣지 케이스에 대해 정상적으로 추론하기는 어려우므로 발생할 수 있는 이슈는 룰 베이스로 제어할 수 있게 하면 운용이 안정된다.
- 물론 모든 이슈를 룰 베이스로 커버할 수 있는 것은 아니므로 최악의 경우를 대비해 추론기로의 접속을 정지할 수 있도록 가동 여부를 제어하는 ACTIVATE 변수만큼은 준비해 두는 것을 권장한다.
6.7.4 구현
-
병렬 마이크로서비스 패턴으로 만든 붓꽃 데이터셋의 이진 분류 추론기를 응용하여 구현한다.
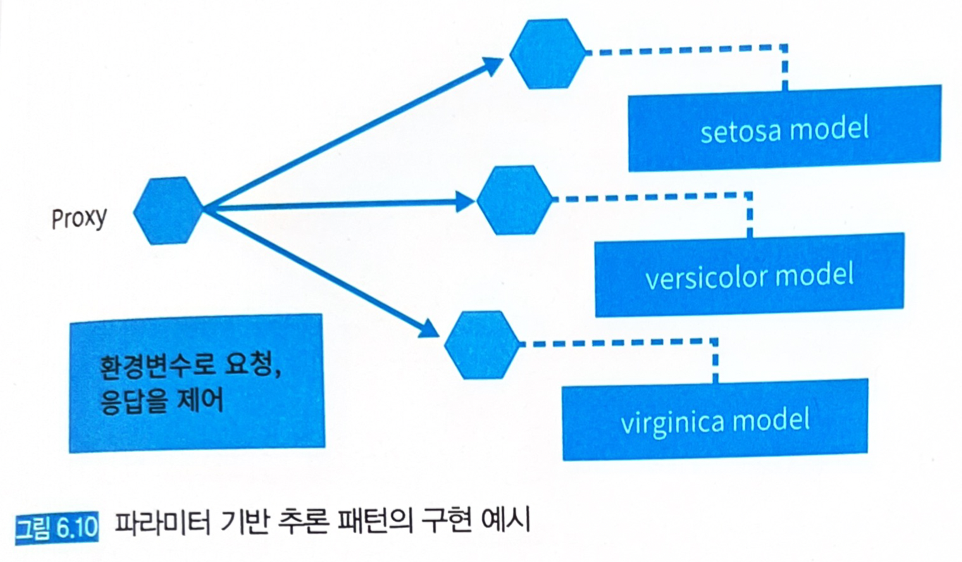
- 모델은 setosa, versicolor, virginica에 대해 각 추론기를 개별 서버로 가동시킨다.
- 프락시가 클라이언트로부터 요청을 받아들여 각 추론기로의 전송을 중개한다.
- 프락시는 추론 결과를 집약하고 임곗값을 통해 필터링한다.
- 프락시에는 접속 중인 추론기를 관리하고, 추론기마다 임곗값을 필터링해 불필요한 추론기에는 요청하지 않도록 하는 기능이 필요하다. 이런 기능은 환경변수를 통해 제어하도록 한다.
-
Docker compose에 환경변수를 설정한다: 원본 코드
version: "3"
services:
proxy:
container_name: proxy
image: shibui/ml-system-in-actions:parameter_based_pattern_proxy_0.0.1
restart: always
environment:
- PLATFORM=docker_compose
- APP_NAME=src.api_composition_proxy.app.proxy:app
- PORT=9000
- SERVICE_SETOSA=service_setosa:8000
- SERVICE_VERSICOLOR=service_versicolor:8001
- SERVICE_VIRGINICA=service_virginica:8002
- THRESHOLD_SETOSA=0.9 # 임곗값 (90%)
- THRESHOLD_VERSICOLOR=0.85 # 임곗값 (85%)
- THRESHOLD_VIRGINICA=0.95 # 임곗값 (95%)
- ACTIVATE_SETOSA=1 # 1 = 유효, 0 = 무효
- ACTIVATE_VERSICOLOR=1 # 1 = 유효, 0 = 무효
- ACTIVATE_VIRGINICA=0 # 1 = 유효, 0 = 무효
ports:
- "9000:9000"
command: ./run.sh
depends_on:
- service_setosa
- service_versicolor
- service_virginica
service_setosa:
container_name: service_setosa
image: shibui/ml-system-in-actions:parameter_based_pattern_setosa_0.0.1
restart: always
environment:
- PLATFORM=docker_compose
- PORT=8000
- MODE=setosa
ports:
- "8000:8000"
command: ./run.sh
service_versicolor:
container_name: service_versicolor
image: shibui/ml-system-in-actions:parameter_based_pattern_versicolor_0.0.1
restart: always
environment:
- PLATFORM=docker_compose
- PORT=8001
- MODE=versicolor
ports:
- "8001:8001"
command: ./run.sh
service_virginica:
container_name: service_virginica
image: shibui/ml-system-in-actions:parameter_based_pattern_virginica_0.0.1
restart: always
environment:
- PLATFORM=docker_compose
- PORT=8002
- MODE=virginica
ports:
- "8002:8002"
command: ./run.sh
- 환경변수로 요청하게 될 추론기와 임곗값을 지정하기 위해 다음과 같이 환경변수를 가져온다: 원본 코드
import os
from logging import getLogger
from typing import Dict
logger = getLogger(__name__)
class ServiceConfigurations:
services: Dict[str, str] = {}
thresholds: Dict[str, float] = {}
default_threshold: float = float(
os.getenv(
"DEFAULT_THRESHOLD",
0.95,
)
)
activates: Dict[str, bool] = {}
for environ in os.environ.keys():
if environ.startswith("SERVICE_"):
url = str(os.getenv(environ))
if not url.startswith("http"):
url = f"http://{url}"
services[environ.lower().replace("service_", "")] = url
if environ.startswith("THRESHOLD_"):
threshold_key = environ.lower().replace("threshold_", "")
thresholds[threshold_key] = float(os.getenv(environ, 0.95))
if environ.startswith("ACTIVATE_"):
activate_key = environ.lower().replace("activate_", "")
if int(os.getenv(environ)) == 1:
activates[activate_key] = True
else:
activates[activate_key] = False
class APIConfigurations:
title = os.getenv("API_TITLE", "ServingPattern")
description = os.getenv("API_DESCRIPTION", "machine learning system serving patterns")
version = os.getenv("API_VERSION", "0.1")
logger.info(f"{ServiceConfigurations.__name__}: {ServiceConfigurations.__dict__}")
logger.info(f"{APIConfigurations.__name__}: {APIConfigurations.__dict__}")
SERVICE_로 시작하는 환경변수는 추론기의 URL을,ACTIVATE_으로 시작하는 환경변수는 추론기의 유효 (1), 무효 (0)를 설정한다.THRESHOLD_로 시작하는 환경변수는 추론기의 임곗값을 설정하는 반면,THRESHOLD_가 지정되지 않은 경우에는 범용적인 임곗값으로DEFAULT_THRESHOLD라는 환경변수를 준비한다.- Docker compose 코드를 부면 virginica 추론기는 무효화했다.
- 프락시: 원본 코드
- FastAPI로 작성한다.
- 배후의 추론기에 요청을 라우팅하는 기능을 구현한다.
- 각 추론기에 요청하여 유효에 해당하는 추론기에서만 추론 결과를 임곗값과 비교해, 임곗값보다 크면 1, 작으면 0을 응답한다.
- 무효한 추론기에도 요청을 보내는 것은 모든 추론기에서 추론 결과를 수집하기 위한 목적이다 (분석이나 서비스 개선을 위함).
import asyncio
import logging
import uuid
from typing import Any, Dict, List
import httpx
from fastapi import APIRouter
from pydantic import BaseModel
from src.api_composition_proxy.configurations import ServiceConfigurations
logger = logging.getLogger(__name__)
router = APIRouter()
# 중략
# 모든 추론기 헬스체크
@router.get("/health/all")
async def health_all() -> Dict[str, Any]:
logger.info(f"GET redirect to: /health")
results = {}
# httpx로 비동기 요청
async with httpx.AsyncClient() as ac:
async def req(ac, service, url):
response = await ac.get(f"{url}/health")
return service, response
tasks = [req(ac, service, url) for service, url in ServiceConfigurations.services.items()]
responses = await asyncio.gather(*tasks)
for service, response in responses:
if response.status_code == 200:
results[service] = "ok"
else:
results[service] = "ng"
return results
# 중략
# 전 추론기에 요청
@router.post("/predict")
async def predict(data: Data) -> Dict[str, Any]:
job_id = str(uuid.uuid4())[:6]
logger.info(f"POST redirect to: /predict as {job_id}")
results = {}
# httpx로 비동기 요청
async with httpx.AsyncClient() as ac:
async def req(ac, service, url, job_id, data):
response = await ac.post(f"{url}/predict", json={"data": data.data}, params={"id": job_id})
return service, response
tasks = [req(ac, service, url, job_id, data) for service, url in ServiceConfigurations.services.items()]
responses = await asyncio.gather(*tasks)
# 추론 결과를 집계
for service, response in responses:
logger.info(f"{service} {job_id} {response.json()}")
if not ServiceConfigurations.activates[service]:
continue
proba = response.json()["prediction"][0]
# 임계치보다 크면 1, 작으면 0
if proba >= ServiceConfigurations.thresholds.get(service, ServiceConfigurations.default_threshold):
results[service] = 1
else:
results[service] = 0
return results
- 시스템을 배포하고 추론 결과를 살펴보자.
$ kubectl -n parameter-based exec -it pod/client bash
# setosa일 것 같은 데이터로 추론을 요청
$ curl \
-X POST \
-H "Content-Type: application/json" \
-d '{"data": [[5.1, 3.5, 1.4, 0.2]]}' \
proxy.parameter-based.svc.cluster.local:9000/predict
# 출력
# {
# "setosa": 1,
# "versicolor": 0
# }
# 어떤 클래스로도 분류되지 않을 법한 데이터로 추론을 요청
$ curl \
-X POST \
-H "Content-Type: application/json" \
-d '{"data": [[50.0, 30.1, 111.4, 110.2]]}' \
proxy.parameter-based.svc.cluster.local:9000/predict
# 출력
# {
# "setosa": 0,
# "versicolor": 0
# }
- 이처럼 추론 결과로 setosa와 versicolor에 관해서만 응답하고 있음을 알 수 있다.
6.7.5 이점
- 룰 베이스에 의한 제어를 추가할 수 있다는 이점이 있다.
- 환경변수 등의 파라미터로 추론 결과나 응답에 대한 규칙을 마련함으로써 머신러닝 모델이 비즈니스 요구에 따라 동작하도록 조정할 수 있다.
6.7.6 검토사항
- 파라미터가 너무 많아져 규칙이 복잡해지면 각 제어 패턴마다 테스트가 필요하게 되고, 시스템 품질을 담보하기 어려워진다.
- 모델을 갱신하면 파라미터나 룰이 더 이상 유효하게 작용하지 않는 경우도 발생한다.
6.8 - 조건분기 추론 패턴
6.8.1 유스케이스
- 상황에 따라 추론 대상에 큰 차이가 있는 경우.
- 여러 개의 추론 모델을 룰 베이스로 나누어 사용할 수 있는 경우.
6.8.2 해결하려는 과제
- 사용자의 상황에 따라 적절한 추론 대상이 변하는 경우가 있다.
- 예를 들어 식사 메뉴를 머신러닝으로 추천하는 유스케이스에서 아침 시간대에 스테이크나 와인을 추천하는 것이 적절하다고는 볼 수 없다.
- 추론 대상을 적절하게 상황에 따라 구분하는 것이 조건 분기 추론 패턴이다.
6.8.3 아키텍처
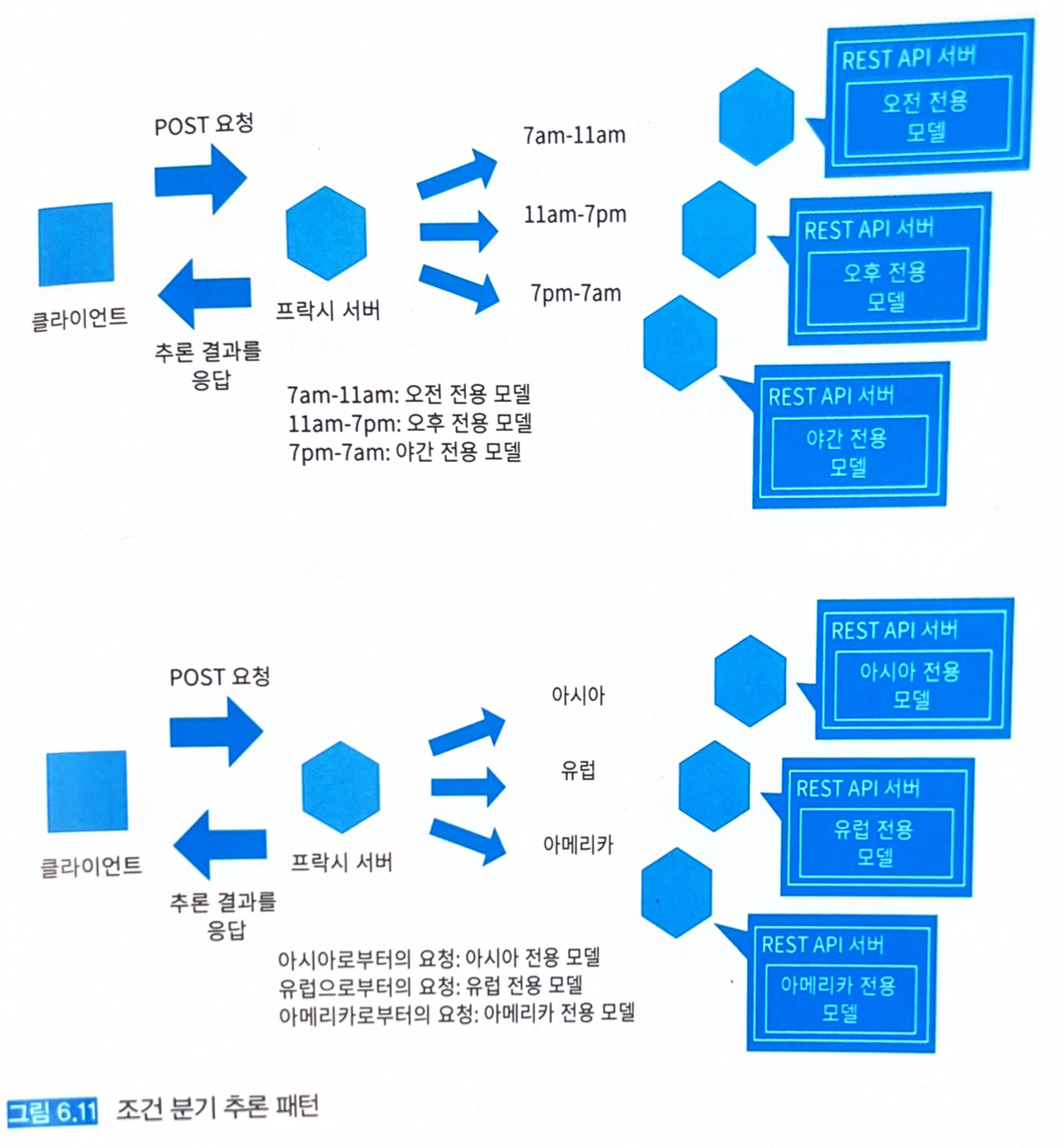
- 각 상황별로 모델을 준비하고 추론기로 배포한다.
- 각 추론기로의 액세스는 프락시로 제어한다.
- 인간의 감각에서 벗어난 상황 분해는 시스템적으로 운용 실수를 초래할 가능성도 있기 때문에 주의가 필요하다.
6.8.4 구현
- 이미지 분류 모델을 조건 분기하는 시스템을 구현해보자.
- 사진에 찍힌 물체를 분류하는 태스크에서는 무엇을 분류하고 싶은지에 따라 다양한 분류 모델을 만들 수 있다.
- 학습 이미지 데이터는 ImageNet을 사용한다.
- 이걸로 분류할 수 있는 1,000개의 클래스는 세상에 존재하는 사물의 극히 일부에 지나지 않으므로, 만약 산에서 자라는 식물의 종류를 분류하고 싶을 때는 식물 분류 모델이 필요하다.
- 그렇다면 사용자가 산 속에서 이미지 분류 요청을 보낼 때는 식물 분류 모델로 분류하고, 산 속이 아닌 경우에는 일반적인 사물 분류를 ImageNet으로 학습한 분류 모델로 추론하는 시스템을 만들어 본다.
- 추론기는 TensorFlow Serving으로 가동시킨다.
- 모델은 ImageNet으로 학습이 완료된 MobileNetV2와 식물 데이터로 학습한 MobileNetV2를 사용한다.
- 앞단에 프락시를 설치하여 요청을 중개하고 메타데이터나 라벨 목록을 제공하는 API의 기능을 하도록 한다.
-
시스템은 쿠버네티스 클러스터에 구축하고, 조건 분기는 Istio로 제어한다.
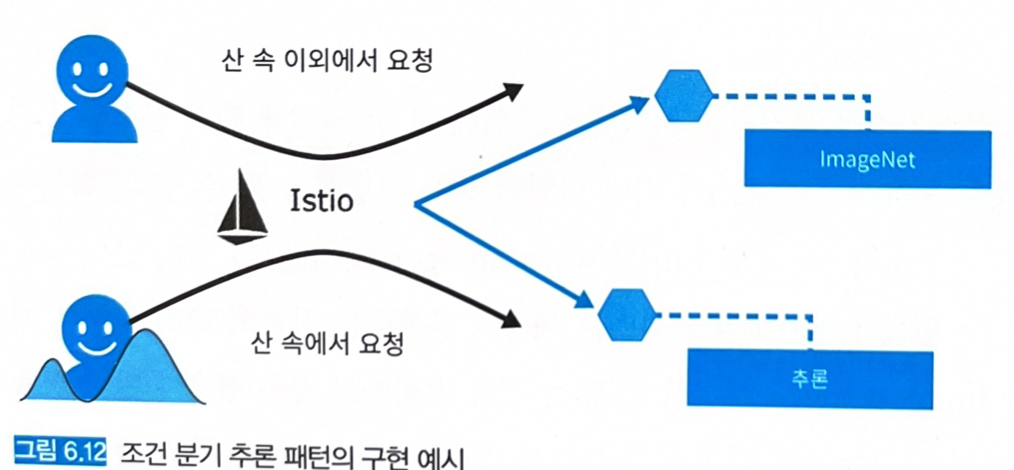
- Istio VirtualService로 요청에 대허에 따라 요청의 전송처를 제어한다:
target: mountain이라는 헤더가 붙은 것은 식물 분류 추론기 프락시로 유도하고, 이외에는 ImageNet 추론기 프락시로 전송한다.
- Istio VirtualService로 요청에 대허에 따라 요청의 전송처를 제어한다:
- 프락시는 FastAPI로 작성한다. 환경변수로 요청처의 TensorFlow Serving이나 메타데이터를 분기한다: 원본 코드
import asyncio
import base64
import io
import logging
import uuid
from typing import Any, Dict, List
import grpc
import httpx
from fastapi import APIRouter
from PIL import Image
from src.api_composition_proxy.backend import request_tfserving
from src.api_composition_proxy.backend.data import Data
from src.api_composition_proxy.configurations import ModelConfigurations, ServiceConfigurations
from tensorflow_serving.apis import prediction_service_pb2_grpc
logger = logging.getLogger(__name__)
router = APIRouter()
channel = grpc.insecure_channel(ServiceConfigurations.grpc)
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
@router.get("/health")
def health() -> Dict[str, str]:
return {"health": "ok"}
@router.get("/label")
def label() -> List[str]:
return ModelConfigurations.labels
@router.get("/metadata")
def metadata() -> Dict[str, Any]:
return {
"data_type": "str",
"data_structure": "(1,1)",
"data_sample": "base64 encoded image file",
"prediction_type": "float32",
"prediction_structure": f"(1,{len(ModelConfigurations.labels)})",
"prediction_sample": "[0.07093159, 0.01558308, 0.01348537, ...]",
}
@router.get("/health/pred")
async def health_pred() -> Dict[str, Any]:
logger.info(f"GET redirect to: /health")
async with httpx.AsyncClient() as ac:
serving_address = (
f"http://{ServiceConfigurations.rest}/v1/models/{ModelConfigurations.model_spec_name}/versions/0/metadata"
)
logger.info(f"health pred : {serving_address}")
r = await ac.get(serving_address)
logger.info(f"health pred res: {r}")
if r.status_code == 200:
return {"health": "ok"}
else:
return {"health": "ng"}
@router.get("/predict/test")
def predict_test() -> Dict[str, Any]:
job_id = str(uuid.uuid4())[:6]
logger.info(f"{job_id} TEST GET redirect to: /predict/test")
image = Data().image_data
bytes_io = io.BytesIO()
image.save(bytes_io, format=image.format)
bytes_io.seek(0)
r = request_tfserving.request_grpc(
stub=stub,
image=bytes_io.read(),
model_spec_name=ModelConfigurations.model_spec_name,
signature_name=ModelConfigurations.signature_name,
timeout_second=ModelConfigurations.timeout_second,
)
logger.info(f"{job_id} prediction: {r}")
return r
@router.post("/predict")
def predict(data: Data) -> Dict[str, Any]:
job_id = str(uuid.uuid4())[:6]
logger.info(f"{job_id} POST redirect to: /predict")
image = base64.b64decode(str(data.image_data))
bytes_io = io.BytesIO(image)
image_data = Image.open(bytes_io)
image_data.save(bytes_io, format=image_data.format)
bytes_io.seek(0)
r = request_tfserving.request_grpc(
stub=stub,
image=bytes_io.read(),
model_spec_name=ModelConfigurations.model_spec_name,
signature_name=ModelConfigurations.signature_name,
timeout_second=ModelConfigurations.timeout_second,
)
logger.info(f"{job_id} prediction: {r}")
return r
- /label 엔드포인트에서는 추론기가 분류하는 라벨의 목록을 응답하고, /metadata 엔드포인트로 요청과 응답 데이터의 정의 및 예시를 제공한다. /predict 엔드포인트에서는 POST 요청된 이미지의 추론 결과를 응답한다.
- 프락시 액세스는 Istio로 제어한다: 원본 코드
apiVersion: apps/v1
kind: Deployment
metadata:
name: mobilenet-v2-proxy
namespace: condition-based-serving
labels:
app: mobilenet-v2-proxy
spec:
replicas: 3
selector:
matchLabels:
app: proxy
template:
metadata:
labels:
app: proxy
version: mobilenet-v2
annotations:
sidecar.istio.io/inject: "true"
sidecar.istio.io/proxyCPU: "128m"
sidecar.istio.io/proxyMemory: "128Mi"
proxy.istio.io/config: "{'concurrency':'8'}"
spec:
containers:
- name: mobilenet-v2-proxy
image: shibui/ml-system-in-actions:condition_based_pattern_proxy_0.0.1
imagePullPolicy: Always
env:
- name: REST
value: mobilenet-v2.condition-based-serving.svc.cluster.local:8501
- name: GRPC
value: mobilenet-v2.condition-based-serving.svc.cluster.local:8500
- name: MODEL_SPEC_NAME
value: mobilenet_v2
- name: SIGNATURE_NAME
value: serving_default
- name: LABEL_PATH
value: ./data/image_net_labels.json
- name: SAMPLE_IMAGE_PATH
value: ./data/cat.jpg
- name: WORKERS
value: "2"
ports:
- containerPort: 8000
resources:
limits:
cpu: 600m
memory: "300Mi"
requests:
cpu: 600m
memory: "300Mi"
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: plant-proxy
namespace: condition-based-serving
labels:
app: plant-proxy
spec:
replicas: 3
selector:
matchLabels:
app: proxy
template:
metadata:
labels:
app: proxy
version: plant
annotations:
sidecar.istio.io/inject: "true"
sidecar.istio.io/proxyCPU: "128m"
sidecar.istio.io/proxyMemory: "128Mi"
proxy.istio.io/config: "{'concurrency':'8'}"
spec:
containers:
- name: plant-proxy
image: shibui/ml-system-in-actions:condition_based_pattern_proxy_0.0.1
imagePullPolicy: Always
env:
- name: REST
value: plant.condition-based-serving.svc.cluster.local:9501
- name: GRPC
value: plant.condition-based-serving.svc.cluster.local:9500
- name: MODEL_SPEC_NAME
value: plant
- name: SIGNATURE_NAME
value: serving_default
- name: LABEL_PATH
value: ./data/plant_labels.json
- name: SAMPLE_IMAGE_PATH
value: ./data/iris.jpg
- name: WORKERS
value: "2"
ports:
- containerPort: 8000
resources:
limits:
cpu: 800m
memory: "500Mi"
requests:
cpu: 800m
memory: "500Mi"
---
apiVersion: v1
kind: Service
metadata:
name: proxy
namespace: condition-based-serving
labels:
app: proxy
spec:
ports:
- name: rest
port: 8000
protocol: TCP
selector:
app: proxy
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: proxy
namespace: condition-based-serving
spec:
host: proxy
trafficPolicy:
loadBalancer:
simple: ROUND_ROBIN
subsets:
- name: mobilenet-v2
labels:
version: mobilenet-v2
- name: plant
labels:
version: plant
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: proxy
namespace: condition-based-serving
spec:
hosts:
- proxy
http:
- match:
- headers:
target:
exact: mountain # target: mountain이면 식물 분류 추론기로 요청
route:
- destination:
host: proxy
subset: plant
timeout: 10s
- route: # 이외에는 ImageNet 추론기로 요청
- destination:
host: proxy
subset: mobilenet-v2
timeout: 10s
- 서비스는 공유하고, VirtualService로 헤더가
target: mountain으로 되어있는 것만 식물 분류 추론기의 프락시로 유도하도록 설정했다. - 배포하고 요청해보자.
$ kubectl -n condition-based-serving exec -it pod/client bash
# 고양이 이미지를 요청 (헤더 미포함)
$ (echo -n '{"image_data": "'; base64 cat.jpg; echo '"}') | \
curl \
-X POST \
-H "Content-Type: application/json" \
-d @- \
proxy.condition-based-serving.svc.cluster.local:8000/predict
# 출력
# "Persian cat"
# 붓꽃 이미지를 요청 (target: mountain 헤더를 포함)
$ (echo -n '{"image_data": "'; base64 iris.jpg; echo '"}') | \
curl \
-X POST \
-H "Content-Type: application/json" \
-H "target: mountain" \
-d @- \
proxy.condition-based-serving.svc.cluster.local:8000/predict
# 출력
# "Iris versicolor"
# 고양이 이미지를 요청 (target: mountain 헤더를 포함)
$ (echo -n '{"image_data": "'; base64 cat.jpg; echo '"}') | \
curl \
-X POST \
-H "Content-Type: application/json" \
-H "target: mountain" \
-d @- \
proxy.condition-based-serving.svc.cluster.local:8000/predict
# 출력
# "background"
# 붓꽃 이미지를 요청 (헤더 미포함)
$ (echo -n '{"image_data": "'; base64 iris.jpg; echo '"}') | \
curl \
-X POST \
-H "Content-Type: application/json" \
-d @- \
proxy.condition-based-serving.svc.cluster.local:8000/predict
# 출력
# "bee"
- 헤더를 포함하여 산 속에 있다고 가정한 경우, 붓꽃 이미지는 Iris versicolor로 잘 인식한 반면 고양이 이미지는 background로 잘 인식되지 않았다 (식물 분류 모델로 고양이 이미지를 분류할 수 없기 때문).
- 헤더를 포함하지 않아 산 속에 있지 않다고 가정한 경우, 붓꽃 이미지는 bee로 엉뚱한 결과를 나타낸 반면 고양이 이미지는 persian cat으로 잘 인식했다 (일반적인 모델로 붓꽃을 분류하기는 어렵다).
6.8.5 이점
- 요청 조건에 따라 추론기를 다르게 사용해 더욱 유연하고 세밀한 추론을 제공할 수 있다.
6.8.6 검토사항
- 모델의 종류가 너무 많아지면 모델의 평가와 개선, 추론기의 운용부하가 증대된다.
- 정말 조건 분기 패턴이 아니라면 해결이 불가능한 것인지, 또는 애초에 머신러닝이 유효한 접근 방식인지를 재검토해야 한다.
6.9 - 안티 패턴 (오프라인 평가 패턴)
6.9.1 상황
- 머신러닝 모델을 오프라인에서 테스트 데이터만을 이용해 평가하고 있는 경우.
6.9.2 구체적인 문제
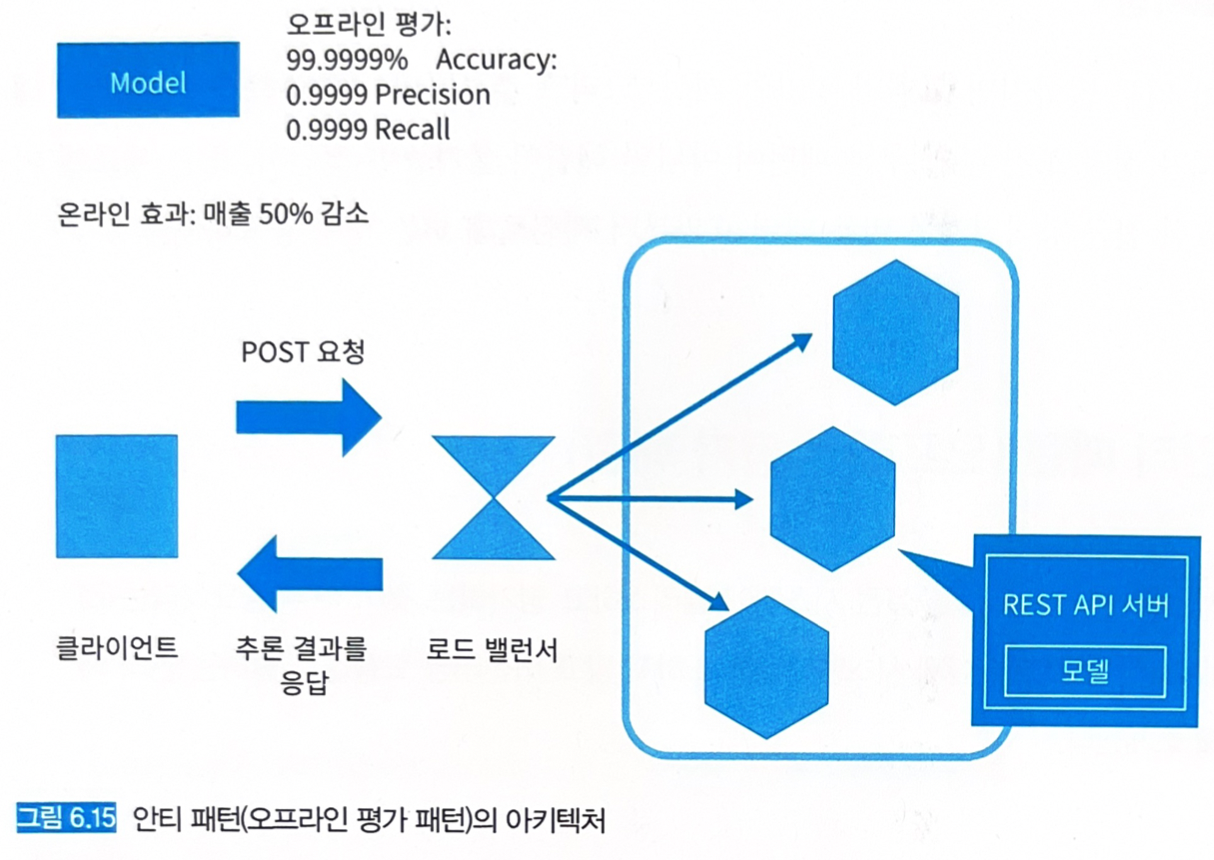
- 모델이 유용한지를 판단하는 기준은 사업이나 효율화로 인한 효과이며, 테스트 데이터가 아니다.
- 테스트 데이터로 99.99%의 정답률을 얻었다고 해도 온라인에서 실제 데이터로 효과를 발휘하지 못한다면 그 모델은 사용 가치가 없다.
6.9.3 이점
- 없다.
6.9.4 과제
- 추론기를 본래의 지표로 평가할 수 없음.
6.9.5 회피 방법
- 우선 모델의 효과를 정량적으로 평가하는 방법을 결정해야 한다.
- 릴리즈 전/후 트래픽을 분할하고 (A/B 그룹), 평가에 필요한 로그를 수집한다.
- 일정 기간 추론기를 가동시켜 로그를 수집한 후 효과를 검증하고 추론기의 유지 여부를 판단한다.